Understanding the Linux Kernel(notes)
Table of Contents
- 1 c1
- 2 c2 内存寻址(段页管理)
- 3 c3 Processes
- 4 c4 Interrupts and Exceptions
- 5 c5 Kernel Synchronization
- 6 c6 Timing Measurements
- 7 c7 Process Scheduling
- 8 c8 Memory Management
- 9 c9. Process Address Space
- 10 c10 System Calls
- 11 c11. Signals
- 12 c12 The Virtual Filesystem
- 13 c13. I/O Architecture and Device Drivers
- 14 c14. Block Device Drivers
- 15 c15. The Page Cache
- 16 c16. Accessing Files
- 17 c17. Page Frame Reclaiming
- 18 c18. The Ext2 and Ext3 Filesystems
- 19 c19. Process Communication
- 20 c20. Program Execution
- 21 总结
内存 c2, c8, c9 进程 c3, c7 中断 c4, IO: 12, 13, 14, 15, 16, 17, 18 其它: 5, 6, 10, 11, 19, 20
内存和io是重点, 没有网络中, 如epoll的实现.
c1-c9看的比较认真, 有笔记, 后面看的比较粗.
1 c1
1.1 微内核
微内核vs巨内核 微内核慢,linux就是微内核
1.2 user mode & kernel mode
- 两个模式是cpu提供的功能。应该理解为在两个模式下cpu可以使用的指令是不同的。或者说可以访问的内存区是不同的。
- 用户程序调用系统调用,然后系统调用的使用cpu的指令进行切换到内核模式。
- 注意 : 这是同一个进程, 一个进程可以运行在用户模式也可以在内核模式。
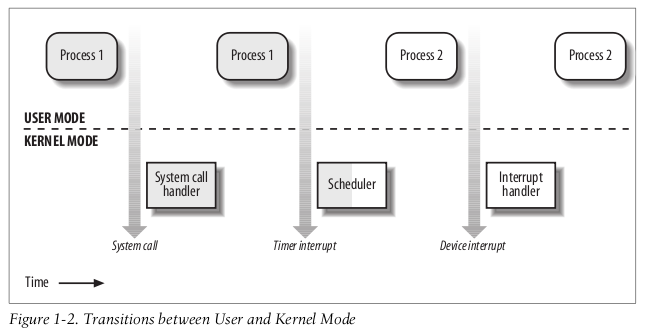
这个图很好的解释了什么情况下会从user mode 进入kernel mode:
user mode 程序调用系统调用
时钟中断(此时内核会调用scheduler, 找一个程序来run)
- 设备中断(此时内核处理设备响应)
- 如对读磁盘操作, 这里把磁盘缓冲区的内容读到内存
- 对写磁盘操作, 这里检查写是否成功.
- 接下来可以调用scheduler, 把那个Process 唤起就是 scheduler 的问题了
内存越界等(Excption)
1.3 内核可重入
内核是可重入的, 意思就是说, 在中断中处理中, 可以再接受中断(某些中断当然是不可重入的)
1.4 内核线程
如oom killer
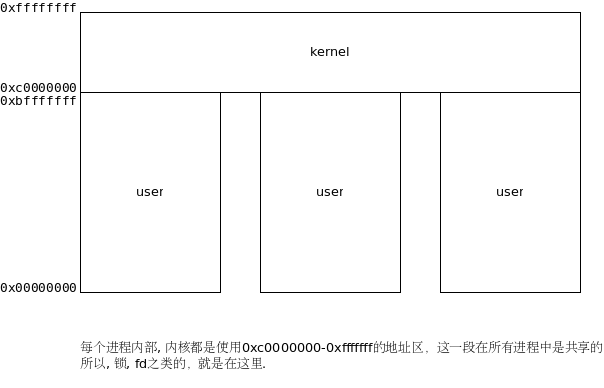
1.6 僵尸进程 (zombie)
这样产生的:
- 父进程fork后, 不去wait它(比如父进程在做sleep() 或其它操作, 总之就是没有调用wait()). 这也就产生了僵尸进程
- 如果父进程挂掉, 这个进程就会被挂到init(1), init总是会wait() 它, 所以不会产生僵尸进程
代码, 子进程退出后, 父进程没去wait它:
int main(){
int pid = fork();
if(pid== 0) {
fprintf(stderr, "child pid: %d\n", getpid());
sleep(1);
fprintf(stderr, "child finish\n");
} else { //Parent
fprintf(stderr, "parent pid: %d\n", getpid());
sleep(100);
fprintf(stderr, "parent finish\n");
}
return 0;
}
$ ./a.out parent pid: 1221 child pid: 1222 child finish
此时pstree看, 子进程挂到 父进程, 状态已经变成Z:
init(1)-+-NetworkManager(1022)-+-dhclient(28101)
| |-bash(31597)---a.out(1221)---a.out(1222)
$ ps -elF
1 Z ning 1222 1221 0 80 0 - 0 exit 0 1 13:16 pts/1 00:00:00 [a.out] <defunct>
1.6.1 如果父进程先结束, 子进程会继续, 并且挂到init上
代码:
int main(){
int pid = fork();
if(pid== 0) {
fprintf(stderr, "child pid: %d\n", getpid());
sleep(2*100);
fprintf(stderr, "child finish\n");
} else { //Parent
fprintf(stderr, "parent pid: %d\n", getpid());
sleep(1);
fprintf(stderr, "parent finish\n");
}
return 0;
}
父进程先退出, 子进程后退出:
$ ./a.out parent pid: 928 child pid: 929 parent finish
此时pstree看, 子进程已经挂到 init上了, 但是这时状态不是Z:
init(1)-+-NetworkManager(1022)-+-dhclient(28101)
| `-{NetworkManager}(1851)
|-a.out(929)
$ ps -elF
F S UID PID PPID C PRI NI ADDR SZ WCHAN RSS PSR STIME TTY TIME CMD
4 S root 1 0 0 80 0 - 5961 poll_s 1888 0 Jan03 ? 00:00:01 /sbin/init
1 S ning 929 1 0 80 0 - 2936 hrtime 320 3 13:11 pts/1 00:00:00 ./a.out
1.6.2 清除僵尸进程
僵尸进程本身是不能被kill的(因为本来就是死的):
ning@ning-laptop:~/idning/langtest/c/zombie-processes$ ps -elF | grep a.out 0 S ning 20696 20023 0 80 0 - 969 hrtime 428 1 08:53 pts/16 00:00:00 ./a.out 1 Z ning 20697 20696 0 80 0 - 0 exit 0 3 08:53 pts/16 00:00:00 [a.out] <defunct> ning@ning-laptop:~/idning/langtest/c/zombie-processes$ kill 20697 (不能kill掉) ning@ning-laptop:~/idning/langtest/c/zombie-processes$ ps -elF | grep a.out 0 S ning 20696 20023 0 80 0 - 969 hrtime 428 1 08:53 pts/16 00:00:00 ./a.out 1 Z ning 20697 20696 0 80 0 - 0 exit 0 3 08:53 pts/16 00:00:00 [a.out] <defunct> ning@ning-laptop:~/idning/langtest/c/zombie-processes$ kill 20696 (解决方法是kill掉附进程) ning@ning-laptop:~/idning/langtest/c/zombie-processes$ ps -elF | grep a.out nothing
解决方法是kill掉父进程, 这样子进程会挂到 init, 并被init wait()
1.6.3 注意
父进程不一定非要调用wait, 忽略 SIGCHILD 也可以(wait就是等待 SIGCHILD ) 参考:
引用:
僵尸进程简而言之就是:子进程退出时,父进程并未对其发出的SIGCHILD信号进行适当处理,导致子进程停留在僵死状态等待其父进程为其收尸,这个状态下的子进程就是僵死进程。 在fork()/execve()过程中,假设子进程结束时父进程仍存在,而父进程fork()之前既没安装SIGCHLD信号处理函数调用waitpid()等待子进程结束,又没有显式忽略该信号,则子进程成为僵死进程,无法正常结束,此时即使是root身份kill -9也不能杀死僵死进程。补救办法是杀死僵尸进程的父进程(僵死进程的父进程必然存在),僵死进程成为"孤儿进程",过继给1号进程init,init始终会负责清理僵死进程。 在unix术语中,一个已经终止但是其父进程尚未对其进行善后处理(获取终止子进程的有关信息,释放它仍占用的资源)的进程称为僵尸进程(zombie)。
2 c2 内存寻址(段页管理)
- 段主要是 隔离的作用!
- linux里面用的段主要是4个: 用户代码段, 用户数据段, 内核代码段, 内核数据段
2.1 逻辑地址, 线性地址, 物理地址
+-----------------+ +-----------------+ +-----------------+ | | 分段单元 | | 分页单元 | | | 逻辑地址 | ----------> | 线性地址 | ---------> | 物理地址 | | | | | | | +-----------------+ +-----------------+ +-----------------+
2.2 硬件中的分段
2.2.2 保护模式中的地址
逻辑地址是段选择器和offset的组合:
2.2.3 段选择器(Segment Selectors)
+------------------+ +----------------+ | | | | | 段选择器 | + | offset | | | | | +------------------+ +----------------+
段选择器有16 bit:
15 3 2 1 0 +-------------------------------------------+---+------+ | index |TI | RPL | +-------------------------------------------+---+------+ TI: Table Indicator RPL Requestor Privilege Level
2.2.4 段寄存器
在cpu中有专门设置的段寄存器, 用于存放段选择器:
cs: 代码段 (code)
有两个bit表示 CPU Privilege Level(CPL) <Linux 只用了0和3 (内核态/用户态)>
ss: 栈段 (stack)
ds: 数据段 (全局和static数据)
es
fs
gs
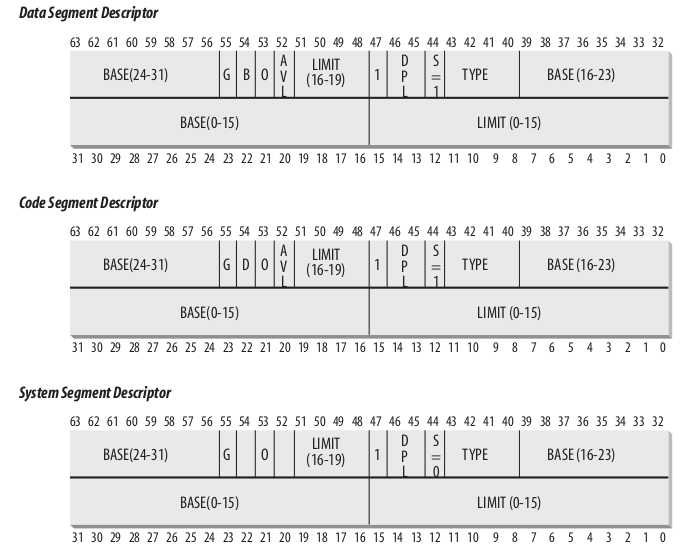
2.2.6 段选择器, 段描述符的关系
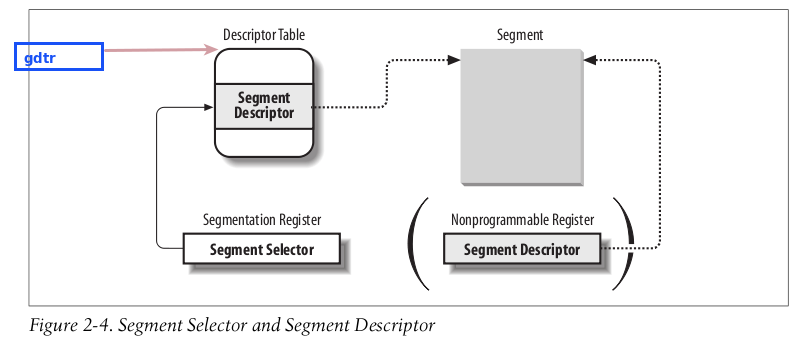
段选择器的字段:
| index: | Identifies the Segment Descriptor entry contained in the GDT or in the LDT (described further in the text following this table). |
|---|---|
| TI: | Table Indicator: specifies whether the Segment Descriptor is included in the GDT (TI = 0) or in the LDT (TI = 1). |
| RPL: | Requestor Privilege Level: specifies the Current Privilege Level of the CPU when the corresponding Segment Selector is loaded into the cs register; it also may be used to selectively weaken the processor privilege level when accessing data segments (see Intel documentation for details). |
计算:
gdtr 中存放的地址 + 段选择器中index*8 = 段描述符的位置.
2.3 Linux 中的分段
因为分段和分页功能上比较重复, Linux实现中对分段用的很少
Linux 2.6 只在80x86架构下使用分段, 只使用4个段:
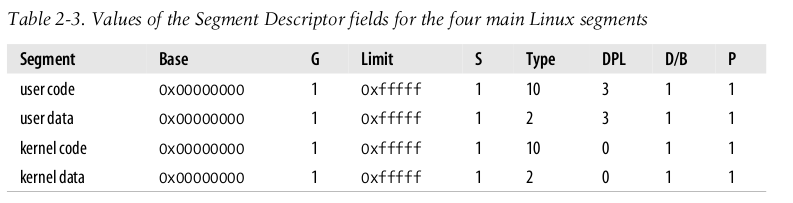
这4个段的线性地址空间都是 0 - 2^32-1 , 意味着
- 所有的进程(不管用户模式还是内核模式) 都使用相同的线性地址空间.
- 因为开始于0x0000000, 线性地址 = 逻辑地址是一样的
2.3.1 Linux 中的GDT
- 单核系统只有一个GDT
- 多核系统, 对每个核有一个GDT
Each GDT includes 18 segment descriptors and 14 null, unused, or reserved entries
2.3.2 Linux中的LDT:
User Application 不使用LDT, 大家共享一个 default_ldt, 可以用 modify_ldt()系统调用 来修改ldt, (Wine使用, 模拟window)
man modify_ldt:
#include <sys/types.h> int modify_ldt(int func, void *ptr, unsigned long bytecount); DESCRIPTION: modify_ldt() reads or writes the local descriptor table (ldt) for a process. The ldt is a per-process memory management table used by the i386 processor. For more information on this table, see an Intel 386 processor handbook.
2.4 硬件中的分页
检查对页的访问是否有权限, 如果没有, 产生PageFault exception
page frame: 物理概念(physical page)
80x86: 控制寄存器cr0中的PG标志控制是否使用硬件提供的分页机制:
PG = 0: linear addresses 就是 physical addresses PG = 1: 使用页表分页.
2.4.1 常规分页
4KB 的page, 两极页表:
如果用一级页表, 当用户稀疏使用了4G线性地址空间,比如只用了0x00000000和0xFFFFFFFF, 就需要 2^20个页表项 (2^32/4k) 需要4M内存. 如果用2级页表, 如果用户实际用的内存较少, 页表所需空间就较小
当然, 如果一个进程使用全部4G空间, 那么一级页表和两极页表都需要占用相同的空间, (二级页表还更多些)
分页机制示意图:
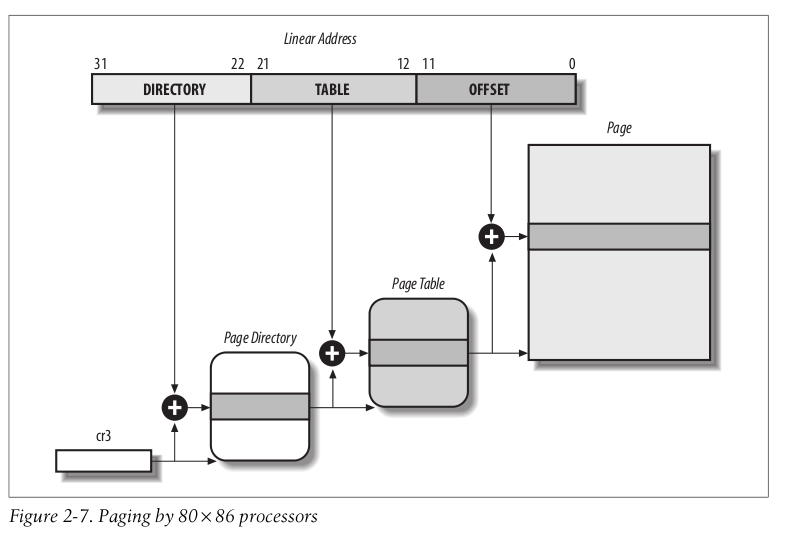
每个进程都必须有自己的 Page Dirrectory, 但是只需要部分的 Page Table .
Page Dirrectory 和 Page Table 都是大小都是1024个页表条目. 页表条目包含:
Present flag : 是否在内存中
20bit物理地址.
Dirty flag
Read/Write flag
- User/Supervisor flag (注意, 只有两种权限级别, 不像段映射, 有4个权限级别)
- 标志为0时, 只允许 CPL < 3 的时候访问(在Linux里面就是内核态)
- 标志为1时, 总是允许访问.
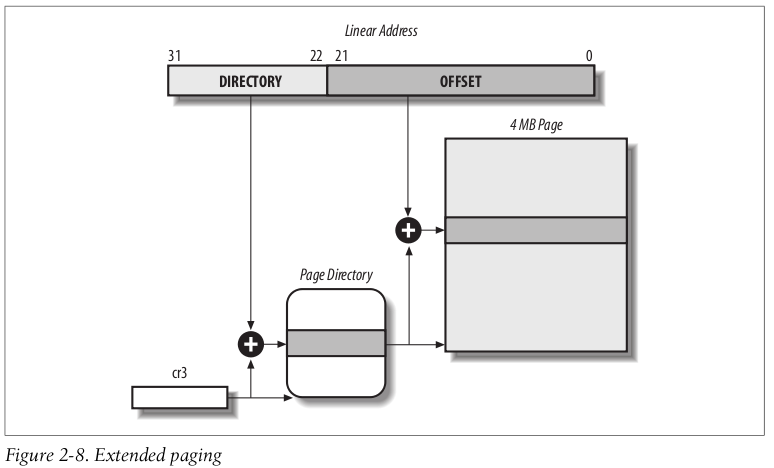
2.4.3 PAE: 允许在32位系统上访问大于4G内存
Physical Address Extension
从 Pentium Pro 开始, Intel 把地址总线宽度从 32 升级到36, 允许访问2^36=64G内存.
PAE is activated by setting the Physical Address Extension (PAE) flag in the cr4 con- trol register. 增加了: A new level of Page Table called the Page Directory Pointer Table (PDPT)
2.4.4 64位架构
64位是 256 TB 地址空间
64位中, 一般使用48位, 如果依然使用4KB的页, 还剩下48-12=36 bit, 这放在两级页表中, Page Directory 和 Page Table 就分别要有2^18条目, 得占用1M空间.
所以, 64位系统中, 一般使用多级页表:
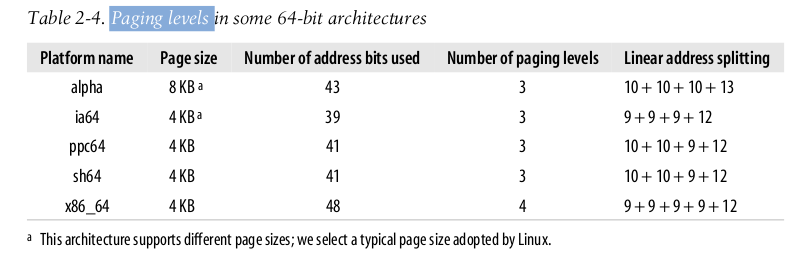
2.4.5 Hardware Cache
Today’s microprocessors have clock rates of several gigahertz, while dynamic RAM (DRAM) chips have access times in the range of hundreds of clock cycles.
L1 cache, L2 cache 之类
2.4.5.1 cache snooping:
在多核架构中, 每个核有自己的cache, 一个核在写数据到cache时, 需要确保另一个核没有对应着一块内存的cache.
2.4.6 TLB(Translation Lookaside Buffers)
80x86 中: to speed up linear address translation
2.5 Linux 中的分页
对32位架构和64位架构使用同样的分页模型
- 2.6.10: 3级页表
- 2.6.11: 4级页表
4级页表:
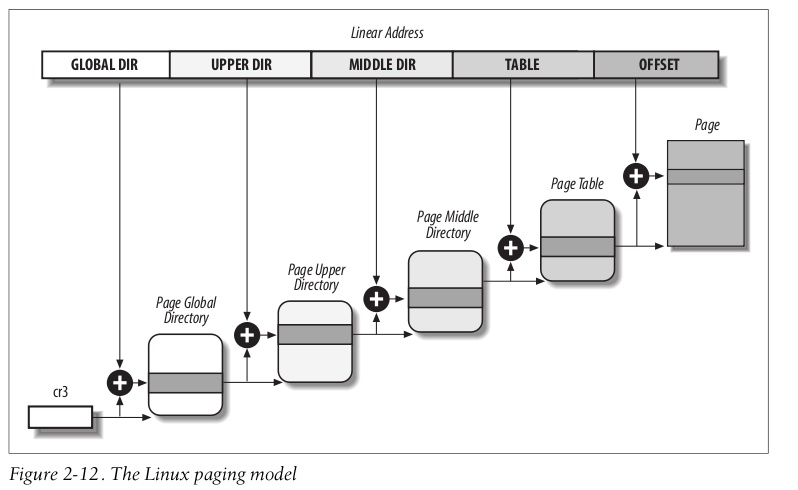
- 对于32位系统: Linux直接把Upper Dirrectory 和Middle Directory 设为只有1个条目, 这样就可以变为2级页表.
- 对于32位+PAE的系统: Linux使用3级页表,
- 对于64位系统, 使用3或4级页表. (见前面的表格)
2.5.1 物理内存Layout
Linux 内核通常在RAM的0x00100000(from the second megabyte)
因为第一M通常是BIOS,
启动时, 内核向BIOS查询可用物理内存大小:
In the early stage of the boot sequence (see Appendix A), the kernel queries the BIOS and learns the size of the physical memory.
之后内核调用 machine_specific_memory_setup() 构造可用空间的一个列表, 例如
Start End Type 0x00000000 0x0009ffff Usable 0x000f0000 0x000fffff Reserved 0x00100000 0x07feffff Usable 0x07ff0000 0x07ff2fff ACPI data 0x07ff3000 0x07ffffff ACPI NVS 0xffff0000 0xffffffff Reserved
arch/i386/kernel/setup.c:
void __init setup_arch(char **cmdline_p)
{
print_memory_map(machine_specific_memory_setup());
max_low_pfn = setup_memory();
paging_init();
register_memory();
}
内核加载后, 一般占3M空间, 也分为代码段, 数据段.
2.5.2 Process Page Table
注意这里说的是线性地址空间:
- Linear addresses from 0x00000000 to 0xbfffffff can be addressed when the process runs in either User or Kernel Mode.
- Linear addresses from 0xc0000000 to 0xffffffff can be addressed only when the process runs in Kernel Mode.
2.5.3 Kernel Page Table
The kernel maintains a set of page tables for its own use, rooted at a so-called master kernel Page Global Directory.
2.6 小结
Linux 中所有的进程(不管用户模式还是内核模式) 都使用相同的线性地址空间: 0 - 2^32-1
3 c3 Processes
Processes are often called tasks or threads in the Linux source code.
LWP: Lightweight Processes, Linux 的多线程就是用LWP实现的.
3.1 Processes, Lightweight Processes, and Threads
- 老的Unix: 进程通过fork产生新进程, 共享代码段, 有不同的数据段(Copy on Write)
- 不支持multithreaded, 内核看到的都是进程, 线程的概念是在用户态实现的(pthread)
- 老的pthread库是用这种实现.
- 新的Unix: 直接支持多线程,
- user programs having many relatively independent execution flows sharing a large portion of the application data structures
- In such systems, a process is composed of several user threads
- Linux 用 Lightweight processes 支持multithreaded
- Examples of POSIX-compliant pthread libraries that use Linux’s lightweight processes are LinuxThreads, Native POSIX Thread Library (NPTL), and IBM’s Next Generation Posix Threading Package (NGPT).
In Linux a thread group is basically a set of lightweight processes that implement a multithreaded application and act as a whole with regards to some system calls such as getpid(), kill(), and _exit().
3.1.1 关于pthread
The code below comes from "Advanced Programing in Unix Environment", it creates a new thread, and prints the process id and thread id for main and new threads.
In the book, it said that in linux, the output of this code would show that two threads have different process ids, because pthread uses lightweight process to emulate thread. But when I ran this code in Ubuntu 12.04, it has kernel 3.2, printed the same pid.
so, does the new linux kernel change the internal implementation of pthread?
#include "apue.h"
#include <pthread.h>
pthread_t ntid;
void printids(const char *s) {
pid_t pid;
pthread_t tid;
pid = getpid();
tid = pthread_self();
printf("%s pid %u tid %u (0x%x)\n",
s, (unsigned int)pid, (unsigned int)tid, (unsigned int)tid);
}
void *thread_fn(void* arg) {
printids("new thread: ");
return (void *)0;
}
int main(void) {
int err;
err = pthread_create(&ntid, NULL, thread_fn, NULL);
if (err != 0)
err_quit("can't create thread: %s\n", strerror(err));
printids("main thread: ");
sleep(1);
return 0;
}
On Linux pthread uses the clone syscall with a special flag CLONE_THREAD.
See the documentation of clone syscall:
CLONE_THREAD (since Linux 2.4.0-test8):
If CLONE_THREAD is set, the child is placed in the same thread group as the calling process. To make the remainder of the discussion of CLONE_THREAD more readable, the term "thread" is used to refer to the processes within a thread group. Thread groups were a feature added in Linux 2.4 to support the POSIX threads notion of a set of threads that share a single PID. Internally, this shared PID is the so-called thread group identifier (TGID) for the thread group. Since Linux 2.4, calls to getpid(2) return the TGID of the caller.
3.1.2 LinuxThreads 和NPTL
一个系统里面的pthread实现只会是两种之一, 可以用下面这个命令查询本系统使用的pthread版本:
getconf GNU_LIBPTHREAD_VERSION
3.2 Process Descriptor
进程描述符
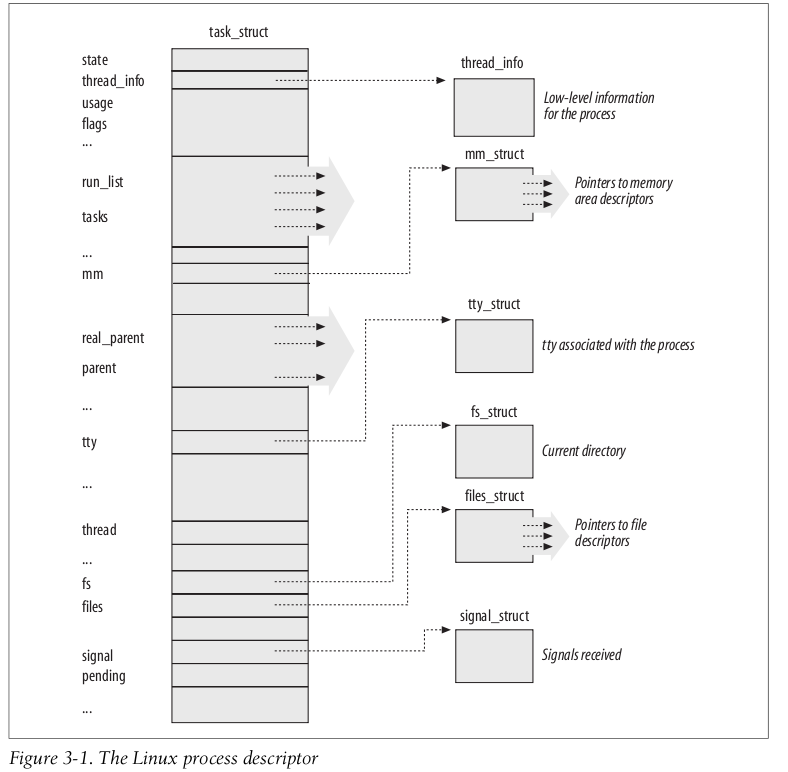
注意内核里面 没有thread 的概念.
进程到Process Descriptor 的一一对应关系, 是通过 Process Descriptor结构的地址值确定的.
3.2.1 能有多少个进程
by default, the maximum PID number is 32,767 (PID_MAX_DEFAULT - 1) , 32位系统最多3w个进程.
the system administrator may reduce this limit by writing a smaller value into the /proc/sys/kernel/pid_max file
In 64-bit architectures, the system administrator can enlarge the maximum PID number up to 4,194,303
因为内核分配一个pid的时候, 需要确保这个pid没有被用过, 所以需要一个bitmap, 32767个bit, 正好是4k(一个page). 在64位系统中, 如果pid_max设置为 4,194,303, 就可能需要0.5M内存做bitmap, 这些内存一旦用了就不会被释放的.
我们的机器一般都是默认的32767
3.2.2 pid在thread group中
在一个thread group 中的进程, 从用户看来pid相等, 实际上, 内核中它们的pid不相等, 是因为getpid 返回的是 tgid .
To comply with this standard, Linux makes use of thread groups. The identifier shared by the threads is the PID of the thread group leader, that is, the PID of the first lightweight process in the group;
it is stored in the tgid field of the process descriptors. The getpid() system call returns the value of tgid relative to the current process instead of the value of pid, so all the threads of a multithreaded application share the same identifier
注意: 但是 kill() 的时候用的是pid.
因为内核中 内核栈后面有意个指向 Process Descriptor 的指针, 所以:
the kernel can easily obtain the address of the thread_info Structure of the process currently running on a CPU from the value of the esp register:
current_thread_info() 这个函数用的非常多
3.2.3 process list
用内核的双链表结构
不同优先级:
truct list_head [140]; #queue The 140 heads of the priority lists
四个hash表用于从id到 Process Descriptor 的映射:
Hash table type Field name Description PIDTYPE_PID pid PID of the process PIDTYPE_TGID tgid PID of thread group leader process PIDTYPE_PGID pgrp PID of the group leader process PIDTYPE_SID session PID of the session leader process
用于pid的hash函数:
unsigned long hash_long(unsigned long val, unsigned int bits)
{
unsigned long hash = val * 0x9e370001UL;
return hash >> (32 - bits);
}
这个数字0x9e370001UL, 是一个质数. 而且比较容易算(二进制中1的位数较少)
A process wishing to wait for a specific condition can invoke any of the functions shown in the following list.:
The sleep_on() function operates on the current process:
void sleep_on(wait_queue_head_t *wq)
{
wait_queue_t wait;
init_waitqueue_entry(&wait, current);
current->state = TASK_UNINTERRUPTIBLE;
add_wait_queue(wq,&wait); /* wq points to the wait queue head */
schedule();
remove_wait_queue(wq, &wait);
}
3.2.4 Process 资源限制
| RLIMIT_AS: | The maximum size of process address space, in bytes. The kernel checks this value when the process uses malloc( ) or a related function to enlarge its address space (see the section The Process’s Address Space” in Chapter 9). |
|---|---|
| RLIMIT_CORE: | The maximum core dump file size, in bytes. The kernel checks this value when a process is aborted, before creating a core file in the current directory of the process (see the section Actions Performed upon Delivering a Signal” in Chapter 11). If the limit is 0, the kernel won’t create the file. |
| RLIMIT_CPU: | The maximum CPU time for the process, in seconds. If the process exceeds the limit, the ker- nel sends it a SIGXCPU signal, and then, if the process doesn’t terminate, a SIGKILL sig- nal (see Chapter 11). |
| RLIMIT_DATA: | The maximum heap size , in bytes. The kernel checks this value before expanding the heap of the process (see the section “Managing the Heap” in Chapter 9). |
| RLIMIT_FSIZE: | The maximum file size allowed, in bytes. If the process tries to enlarge a file to a size greater than this value, the kernel sends it a SIGXFSZ signal. |
| RLIMIT_LOCKS: | Maximum number of file locks (currently, not enforced). |
| RLIMIT_NOFILE: |
3.3 Process Switch
3.3.1 Hardware Context 切换
2.6以前, 使用 far jmp 来实现硬件层次的切换, 自动保存寄存器的值. But Linux 2.6 uses software to perform a process switch for the following reasons:
总之就是保存各种寄存器. MMX< FPU, SSE之类.
3.3.2 schedule() 函数
every process switch consists of two steps: 1. Switching the Page Global Directory to install a new address space; we’ll describe this step in Chapter 9. 2. Switching the Kernel Mode stack and the hardware context, which provides all the information needed by the kernel to execute the new process, including the CPU registers.
3.4 Create Processes
3.4.1 内核底层的clone
各种flag:
| CLONE_VM: | Shares the memory descriptor and all Page Tables (see Chapter 9). 共享地址空间. |
|---|---|
| CLONE_FS: | Shares the table that identifies the root directory and the current working directory, as well as the value of the bitmask used to mask the initial file permissions of a new file (the so-called file umask). |
| CLONE_FILES: | Shares the table that identifies the open files (see Chapter 12). 共享打开的文件fd. |
| CLONE_SIGHAND: | Shares the tables that identify the signal handlers and the blocked and pending signals (see Chapter 11). If this flag is true, the CLONE_VM flag must also be set. 共享sighandler(比如nohup 先设置了SIGHANDLER, 再打开子进程的时候, 肯定就设置了这个标记) |
| CLONE_PTRACE: | If traced, the parent wants the child to be traced too. Furthermore, the debugger may want to trace the child on its own; in this case, the kernel forces the flag to 1. 跟踪模式 |
| CLONE_VFORK: | Set when the system call issued is a vfork( ) (see later in this section). ... |
| CLONE_STOPPED: | Forces the child to start in the TASK_STOPPED state. |
3.4.2 clone( ), fork( ), and vfork( )
clone 创建线程, 基本上就是上面sys_clone系统调用.
- fork: 用clone实现, 设置了SIGCHILD, 所有的flag都未设置 (TODO: ? 难道CLONE_SIGHAND也没设置?)
- 它的chile_stack参数是父进程当前堆栈指针(所以创建完成后, 父子两个进程的堆栈指针是一样的.)
- copy on write 保证堆栈上有写操作的时候, 父子进程就会使用不同的堆栈.
- vfork (create a child process and block parent)
- 设置SIGCHILD, CLONE_VM, CLONE_VFORK,
- vfork 阻塞父进程的执行, 一直到子进程退出或执行一个新的程序为止.
3.4.2.1 man clone(库函数)
#define _GNU_SOURCE
#include <sched.h>
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, struct user_desc *tls, pid_t *ctid */ );
It is actually a library function layered on top of the underlying clone() system call, hereinafter referred to as sys_clone.
(这个clone是一个library函数, 下层是通过sys_clone系统调用实现, sys_clone没有 fn, arg参数, 这两个参数是 clone这个库函数加上的.)
这个clone是用于实现thread的. 允许设置共享内存, 栈空间, 栈位置等.
3.4.3 do_fork() 函数
do_fork() 负责处理clone(), fork(), vfork() 系统调用.
几个重要步骤: 1. 查找pidmap_array 位图, 为子进程分配新的pid 2. If the child will run on the same CPU as the parent, and parent and child do not share the same set of page tables (CLONE_VM flag cleared), it then forces the child to run before the parent by inserting it into the parent’s runqueue right before the parent.
This simple step yields better performance if the child flushes its address space and executes a new program right after the forking. If we let the parent run first, the Copy On Write mechanism would give rise to a series of unnecessary page duplications.
这种情况, 强迫 子进程先运行,
3.5 内核线程
内核中, 周期性执行, 只运行在内核态, 用kernel_thread() 函数创建.
The function essentially invokes do_fork() as follows:
do_fork(flags|CLONE_VM|CLONE_UNTRACED, 0, pregs, 0, NULL, NULL);
常见的内核线程:
- keventd (also called events)
- Executes the functions in the keventd_wq workqueue (see Chapter 4).
- kapmd
- Handles the events related to the Advanced Power Management (APM).
- kswapd
- Reclaims memory, as described in the section “Periodic Reclaiming” in Chapter 17.
- pdflush
- Flushes “dirty” buffers to disk to reclaim memory, as described in the section “The pdflush Kernel Threads” in Chapter 15.
- kblockd
- Executes the functions in the kblockd_workqueue workqueue. Essentially, it periodically activates the block device drivers, as described in the section “Activating the Block Device Driver” in Chapter 14.
- ksoftirqd
- Runs the tasklets (see section “Softirqs and Tasklets” in Chapter 4); there is one of these kernel threads for each CPU in the system.
3.5.1 pdflush
参考: http://www.westnet.com/~gsmith/content/linux-pdflush.htm http://www.linuxjournal.com/article/6931
可能有 2 - 8 个pdflush threads.
You can monitor how many are active by looking at /proc/sys/vm/nr_pdflush_threads.
- Whenever all existing pdflush threads are busy for at least one second, an additional pdflush daemon is spawned.
- Each time a second has passed without any pdflush activity, one of the threads is removed
调优:
- /proc/sys/vm/dirty_writeback_centisecs (default 500):
- In hundredths of a second, this is how often pdflush wakes up to write data to disk.
- The default wakes up the two (or more) active threads every five seconds.
- 减小这个值会让pdflush 更加激进.
- /proc/sys/vm/dirty_expire_centiseconds (default 3000):
- In hundredths of a second, how long data can be in the page cache before it's considered expired and must be written at the next opportunity. Note that this default is very long: a full 30 seconds. That means that under normal circumstances, unless you write enough to trigger the other pdflush method, Linux won't actually commit anything you write until 30 seconds later.
- 多长时间以上的page需要flush
- /proc/sys/vm/dirty_background_ratio (default 10):
- Maximum percentage of active that can be filled with dirty pages before pdflush begins to write them
- /proc/sys/vm/dirty_ratio (default 40):
- Maximum percentage of total memory that can be filled with dirty pages before processes are forced to write dirty buffers themselves during their time slice instead of being allowed to do more writes.
3.6 进程0 & 进程1
- 进程0: 所有进程的祖先, (idle进程)
- 是一个内核线程
- 执行 cpu_idle() 函数, 本质上是在开中断的情况下重复执行hlt指令
- 只有当没有其它进程处于TASK_RUNNING 状态时, 调度程序才选择进程0
- 多核系统中, 每个核都有一个进程0 (TODO: how)
- 进程1: init进程, 由进程0创建,
- 创建后调用 execve() 装载init二进制, 不是内核线程.
3.7 Destorying Processes
- exit_group() 系统调用, 终止整个线程组, 对应 c库函数exit()
- exit() 系统调用, 终止一个线程 对应 pthread_exit()
4 c4 Interrupts and Exceptions
- Interrupts Asynchronous interrupts: 硬件 发出的.
- 可屏蔽中断
- 不可屏蔽中断
- 极少数. Only a few critical events (such as hardware failures)
- Exceptions Synchronous interrupts: cpu执行完一个指令后发出的
- Processor-detected exceptions (怎么翻译)
- Faults
- 如Page Fault Exception Handler
- Traps
- 如debugger
Aborts
- Programmed exceptions(程序主动触发)
- int or int3 instructions
- into (check for overflow) and bound (check on address bound) instructions
exception 和interrupt 是intel的术语.
4.1 Interrupts and Exceptions
4.1.1 Interrupt
4.1.1.1 Interrupt handling
- 非常轻量, 内核必须尽量处理尽量多的中断, 这样内核就必须把Interrupt Handler 做的很轻. 比如有数据ready时, 中断处理程序只是简单的做一个标记, 然后通知相应的程序, 而不会在中断处理程序里面拷贝数据到内存.
- 可重入
4.1.1.2 IRQs (Interrupt ReQuests)
每个硬件都有一个 Interrupt ReQuest (IRQ) line 引脚
所有硬件的引脚 都连到 Programmable Interrupt Controller(PIC)
- PIC (Programmable Interrupt Controller)
Monitors the IRQ lines, checking for raised signals. If two or more IRQ lines are raised, selects the one having the lower pin number.
- If a raised signal occurs on an IRQ line:
- Converts the raised signal received into a corresponding vector.
- Stores the vector in an Interrupt Controller I/O port, thus allowing the CPU to read it via the data bus.
- Sends a raised signal to the processor INTR pin—that is, issues an interrupt. (给CPU的INTR引脚发信号)
- Waits until the CPU acknowledges the interrupt signal by writing into one of the Programmable Interrupt Controllers (PIC) I/O ports; when this occurs, clears the INTR line.
Goes back to step 1.
IRQ线可以屏蔽.
4.1.1.2.1 老的PIC 的硬件结构
2个8259芯片, 第二个向上连在第一个的一个引脚, 可以处理15个IRQ线
Traditional PICs are implemented by connecting “in cascade” two 8259A-style external chips. Each chip can handle up to eight different IRQ input lines. Because the INT output line of the slave PIC is connected to the IRQ2 pin of the master PIC, the number of available IRQ lines is limited to 15.
4.1.1.2.2 新的PIC 的硬件结构 The Advanced Programmable Interrupt Controller (APIC)
Pentium III 以后有APIC
多核系统中, 每个核都应该可以处理中断, 所以有一个中断总线, APIC和CPU都连到这个总线上, 有总线仲裁/路由机制:
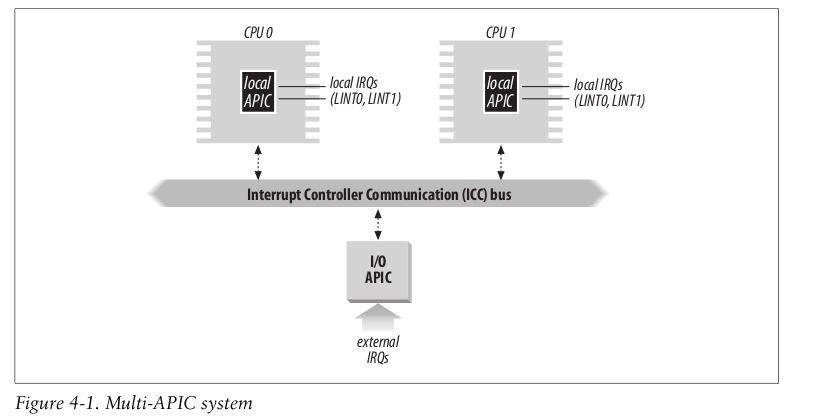
硬件终端可以有两种处理方式:
- Static distribution
- 指定中断有某个CPU处理.
- Dynamic distribution
- 信号被分发到CPU 中 priority 最小的一个. (这个priority可以编程修改)
CPU之间也能发送中断.
4.1.2 Exceptions
- 0 “Divide error” (fault)
- Raised when a program issues an integer division by 0.
- 1 “Debug” (trap or fault)
- Raised when the TF flag of eflags is set (quite useful to implement single-step execution of a debugged program) or when the address of an instruction or operand falls within the range of an active debug register (see the section “Hardware Context” in Chapter 3).
- 3 “Breakpoint” (trap)
- Caused by an int3 (breakpoint) instruction (usually inserted by a debugger).
- 4 “Overflow” (trap)
- An into (check for overflow) instruction has been executed while the OF (overflow) flag of eflags is set.
8 “Double fault”
11 “Segment not present” (fault)
12 “Stack segment fault” (fault)
14 “Page Fault” (fault)
内核收到中断后,通常会向进程发送信号(这就是我们段错误的时候是收到信号的原因)
Table 4-1. Signals sent by the exception handlers # Exception Exception handler Signal 0 Divide error divide_error( ) SIGFPE 1 Debug debug( ) SIGTRAP 2 NMI nmi( ) None 3 Breakpoint int3( ) SIGTRAP 4 Overflow overflow( ) SIGSEGV 5 Bounds check bounds( ) SIGSEGV 6 Invalid opcode invalid_op( ) SIGILL 7 Device not available device_not_available( ) None 8 Double fault doublefault_fn() None 9 Coprocessor segment overrun coprocessor_segment_overrun( ) SIGFPE 10 Invalid TSS invalid_TSS( ) SIGSEGV 11 Segment not present segment_not_present( ) SIGBUS 12 Stack segment fault stack_segment( ) SIGBUS 13 General protection general_protection( ) SIGSEGV 14 Page Fault page_fault( ) SIGSEGV 15 Intel-reserved None None 16 Floating-point error coprocessor_error( ) SIGFPE 17 Alignment check alignment_check( ) SIGBUS 18 Machine check machine_check() None 19 SIMD floating point simd_coprocessor_error() SIGFPE
4.3 Initializing the Interrupt Descriptor Table
Intel 提供三种 Interrupt, Trap, and System Gates, 权限不同, o, 比较复杂:
set_trap_gate(0,÷_error); set_trap_gate(1,&debug); set_intr_gate(2,&nmi); set_system_intr_gate(3,&int3); set_system_gate(4,&overflow); set_system_gate(5,&bounds); set_trap_gate(6,&invalid_op); set_trap_gate(7,&device_not_available); set_task_gate(8,31); set_trap_gate(9,&coprocessor_segment_overrun); set_trap_gate(10,&invalid_TSS); set_trap_gate(11,&segment_not_present); set_trap_gate(12,&stack_segment); set_trap_gate(13,&general_protection); set_intr_gate(14,&page_fault); ...
4.4 Exception Handling
通常是发信号到响应进程.
Most exceptions issued by the CPU are interpreted by Linux as error conditions. When one of them occurs, the kernel sends a signal to the process that caused the exception to notify it of an anomalous condition.
例如:
If, for instance, a process performs a division by zero, the CPU raises a “Divide error” exception, and the corresponding exception handler sends a SIGFPE signal to the current process, which then takes the necessary steps to recover or (if no signal handler is set for that signal) abort.
current->thread.error_code = error_code; current->thread.trap_no = vector; force_sig(sig_number, current);
The current process takes care of the signal right after the termination of the exception handler.
The signal will be handled either in User Mode by the process’s own signal handler (if it exists) or in Kernel Mode. In the latter case, the kernel usually kills the process (see Chapter 11). The signals sent by the exception handlers are listed in Table 4-1.
4.5 Interrupt Handling(硬件产生的)
this approach does not hold for interrupts, because they frequently arrive long after the process to which they are related
前面方法不适用, 因为当前进程和中断并没有关系.
三种:
- I/O interrupts
- An I/O device requires attention; the corresponding interrupt handler must query the device to determine the proper course of action. We cover this type of interrupt in the later section “I/O Interrupt Handling.”
- Timer interrupts
- Some timer, either a local APIC timer or an external timer, has issued an interrupt; this kind of interrupt tells the kernel that a fixed-time interval has elapsed. These interrupts are handled mostly as I/O interrupts; we discuss the peculiar characteristics of timer interrupts in Chapter 6.
- Interprocessor interrupts
- A CPU issued an interrupt to another CPU of a multiprocessor system. We cover such interrupts in the later section “Interprocessor Interrupt Handling.”
Table 4-3. An example of IRQ assignment to I/O devices:
IRQ INT Hardware device 0 32 Timer Timer 必须是0号IRQ线. 1 33 Keyboard 2 34 PIC cascading 3 35 Second serial port 4 36 First serial port 6 38 Floppy disk 8 40 System clock 10 42 Network interface 11 43 USB port, sound card 12 44 PS/2 mouse 13 45 Mathematical coprocessor 14 46 EIDE disk controller’s first chain 15 47 EIDE disk controller’s second chain
4.5.1 IRQ在多处理器系统上的分发
Linux 遵守对称多处理器模型(SMP), 这意味着, 内核对每个CPU都不应该有偏爱.
内核试图以轮转的方式把来自硬件的IRQ信号在多个CPU之间分发, 所有CPU服务于I/O中断的执行时间片几乎相同.
这是由硬件完成的, 但是有的硬件存在问题, Linux 使用kirqd的特殊内核线程来纠正对CPU进行的IRQ自动分配
4.5.1.1 CPU的IRQ亲和力
多APIC系统中, 通过修改APIC中断重定向表, 可以把指定中断发到特定的CPU上.
kirqd内核线程定期执行 do_irq_balance() 函数, 它记录最近时间内每个cpu的终端次数, 如果发现负载不均衡, 就把IRQ从一个CPU转到另一个CPU.
4.5.1.2 例子:网卡多队列的中断绑定
如果大家用的万兆网卡跑linux或者nginx做大规模的负载均衡,那么肯定会遇到网卡中断占耗尽一个CPU的情况,会发现有一个ksoftirqd进程耗CPU非常厉害。这个时候就需要把万兆网卡的多个队列分别绑定到不同的核上。简单的在自己的笔记本上测试一下把单个中断绑定到指定CPU的方式。
ning@ning-laptop:~/test$ cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
0: 1120 78 73 89 IO-APIC-edge timer
1: 8372 8326 4485 1256 IO-APIC-edge i8042
8: 0 0 0 1 IO-APIC-edge rtc0
9: 919824 902422 945216 917506 IO-APIC-fasteoi acpi
12: 70724 74831 73671 130628 IO-APIC-edge i8042
14: 3836954 375689 389297 391612 IO-APIC-edge ata_piix
15: 0 0 0 0 IO-APIC-edge ata_piix
17: 228109 213 105882 40581 IO-APIC-fasteoi ata_piix, HDA Intel
19: 2129264 2483519 2266058 1798885 IO-APIC-fasteoi ehci_hcd:usb2
23: 548565 795696 859954 207891 IO-APIC-fasteoi ehci_hcd:usb1
27: 929 23923 1717 2311 PCI-MSI-edge eth0
28: 60226455 7787039 7893406 8392505 PCI-MSI-edge iwlagn
29: 1156981 1577957 3826559 1869343 PCI-MSI-edge i915@pci:0000:00:02.0
NMI: 0 0 0 0 Non-maskable interrupts
LOC: 88922568 93984839 101969505 97218270 Local timer interrupts
SPU: 0 0 0 0 Spurious interrupts
PMI: 0 0 0 0 Performance monitoring interrupts
PND: 0 0 0 0 Performance pending work
RES: 15963006 16173515 13643964 13852799 Rescheduling interrupts
CAL: 264642 254329 620940 555868 Function call interrupts
TLB: 2069687 1882570 1553231 1561555 TLB shootdowns
TRM: 0 0 0 0 Thermal event interrupts
THR: 0 0 0 0 Threshold APIC interrupts
MCE: 0 0 0 0 Machine check exceptions
MCP: 1349 1345 1345 1345 Machine check polls
ERR: 0
MIS: 0
通过两次cat:
ning@ning-laptop:~/test$ cat /proc/interrupts | grep iwl 28: 60237470 7787039 7893406 8392505 PCI-MSI-edge iwlagn ning@ning-laptop:~/test$ cat /proc/interrupts | grep iwl 28: 60237488 7787039 7893406 8392505 PCI-MSI-edge iwlagn ning@ning-laptop:~/test$ cat /proc/interrupts | grep iwl 28: 60237512 7787039 7893406 8392505 PCI-MSI-edge iwlagn
这里发现28号中断(iwlagn) 只有CPU0这一列在增加, 说明28号中断绑定在CPU0上.
比如要绑定到CPU3:
echo 4 > /proc/irq/28/smp_affinity
这里:
1 : CPU0 2 : CPU1 4 : CPU2 8 : CPU3
再观察, 发现只有CPU2这一列在增加:
ning@ning-laptop:~/test$ cat /proc/interrupts | grep iwl 28: 60238491 7787039 7893707 8392505 PCI-MSI-edge iwlagn ning@ning-laptop:~/test$ cat /proc/interrupts | grep iwl 28: 60238491 7787039 7893727 8392505 PCI-MSI-edge iwlagn ning@ning-laptop:~/test$ cat /proc/interrupts | grep iwl 28: 60238491 7787039 7893740 8392505 PCI-MSI-edge iwlagn
一个核每秒能处理多少中断?
我们的机器eth中断都绑定在CPU0上面:
$ cat /proc/interrupts | grep eth 49: 273896202 0 0 0 0 0 0 0 0 0 0 0 PCI-MSI-edge eth1-0 50: 2839469681 0 0 0 0 0 0 0 0 0 0 0 PCI-MSI-edge eth1-1 51: 2443166700 0 0 0 0 0 0 0 0 0 0 0 PCI-MSI-edge eth1-2 52: 947194873 0 0 0 0 0 0 0 0 0 0 0 PCI-MSI-edge eth1-3 53: 3035084892 0 0 0 0 0 0 0 0 0 0 0 PCI-MSI-edge eth1-4 54: 2586224100 0 0 0 0 0 0 0 0 0 0 0 PCI-MSI-edge eth1-5 55: 1861561263 0 0 0 0 0 0 0 0 0 0 0 PCI-MSI-edge eth1-6 56: 4154271481 0 0 0 0 0 0 0 0 0 0 0 PCI-MSI-edge eth1-7
$ cat /proc/interrupts | grep eth | awk '{A+=$2} END{print A}' && sleep 10 && cat /proc/interrupts | grep eth | awk '{A+=$2} END{print A}'
18144814547
18145846813 (10s)
大约每秒10w个中断, 这个机器负载不重.
4.5.1.3 把进程绑在核上
查看:
$ taskset -p 40234 pid 40234's current affinity mask: fff
说明每个核都可能运行.
设置:
ning@ning-laptop ~/test$ taskset -p 7537 pid 7537's current affinity mask: f ning@ning-laptop ~/test$ taskset -p e 7537 pid 7537's current affinity mask: f pid 7537's new affinity mask: e ning@ning-laptop ~/test$ taskset -p 7537 pid 7537's current affinity mask: e
另外一种格式set:
taskset -pc 0,3,7-11 700
进程启动时指定CPU:
taskset -c 1 ./redis-server ../redis.conf
4.5.1.4 网卡多队列
对于万兆网卡, 一把提供多个中断号(多队列), 如果中断都绑在一个核上, 就悲剧了.
有多个RSS队列.
英特尔 X520万兆网卡里,最大可以同时支持128个队列,足以满足当前主流的服务器CPU配置。
开启多队列:
sed -i 's/e1000/igb/g' /etc/modprobe.conf echo "options igb RSS=8,8" >> /etc/modprobe.conf
4.5.1.5 千兆网卡多队列
4.5.1.5.1 是否支持
http://blog.csdn.net/turkeyzhou/article/details/7528182
#lspci -vvv
Ethernet controller的条目内容,如果有MSI-X && Enable+ && TabSize > 1,则该网卡是多队列网卡,如图4.4所示。
图4.4 lspci内容
Message Signaled Interrupts(MSI)是PCI规范的一个实现,可以突破CPU 256条interrupt的限制,使每个设备具有多个中断线变成可能,多队列网卡驱动给每个queue申请了MSI。MSI-X是MSI数组,Enable+指使能,TabSize是数组大小。
02:00.1 Ethernet controller: Intel Corporation: Unknown device 150e (rev 01)
Subsystem: Intel Corporation: Unknown device 0000
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr- Stepping- SERR- FastB2B-
Status: Cap+ 66Mhz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR-
Latency: 0, Cache Line Size 10
Interrupt: pin B routed to IRQ 30
Region 0: Memory at 94800000 (32-bit, non-prefetchable) [size=512K]
Region 2: I/O ports at 5000 [size=32]
Region 3: Memory at 94900000 (32-bit, non-prefetchable) [size=16K]
Capabilities: [40] Power Management version 3
Flags: PMEClk- DSI+ D1- D2- AuxCurrent=0mA PME(D0+,D1-,D2-,D3hot+,D3cold+)
Status: D0 PME-Enable- DSel=0 DScale=1 PME-
Capabilities: [50] Message Signalled Interrupts: 64bit+ Queue=0/0 Enable-
Address: 0000000000000000 Data: 0000
Capabilities: [70] MSI-X: Enable+ Mask- TabSize=10
Vector table: BAR=3 offset=00000000
PBA: BAR=3 offset=00002000
Capabilities: [a0] Express Endpoint IRQ 0
Device: Supported: MaxPayload 512 bytes, PhantFunc 0, ExtTag-
Device: Latency L0s <512ns, L1 <64us
Device: AtnBtn- AtnInd- PwrInd-
Device: Errors: Correctable+ Non-Fatal+ Fatal+ Unsupported+
Device: RlxdOrd+ ExtTag- PhantFunc- AuxPwr- NoSnoop+
Device: MaxPayload 128 bytes, MaxReadReq 512 bytes
Link: Supported Speed unknown, Width x4, ASPM L0s L1, Port 2
Link: Latency L0s <4us, L1 <8us
Link: ASPM Disabled RCB 64 bytes CommClk+ ExtSynch-
Link: Speed unknown, Width x4
Capabilities: [100] Advanced Error Reporting
Capabilities: [140] Device Serial Number ab-fb-2b-ff-ff-c7-0b-20
Capabilities: [1a0] Unknown (23)
还有种通用的方式,直接查看 interrupts 文件,看关键字 MSI 就知道了:
# grep -i msi /proc/interrupts
3.dmsg:
# dmesg | grep -i msi hpet: hpet2 irq 72 for MSI hpet: hpet3 irq 73 for MSI hpet: hpet4 irq 74 for MSI hpet: hpet5 irq 75 for MSI hpet: hpet6 irq 76 for MSI hpet: hpet7 irq 77 for MSI megaraid_sas 0000:03:00.0: irq 78 for MSI/MSI-X ahci 0000:00:1f.2: irq 79 for MSI/MSI-X igb 0000:02:00.0: irq 80 for MSI/MSI-X igb 0000:02:00.0: irq 81 for MSI/MSI-X igb 0000:02:00.0: Using MSI-X interrupts. 1 rx queue(s), 1 tx queue(s) igb 0000:02:00.1: irq 82 for MSI/MSI-X igb 0000:02:00.1: irq 83 for MSI/MSI-X igb 0000:02:00.1: Using MSI-X interrupts. 1 rx queue(s), 1 tx queue(s) isci 0000:04:00.0: irq 84 for MSI/MSI-X isci 0000:04:00.0: irq 85 for MSI/MSI-X
ethtool:
# ethtool -S eth0 | tail -20 os2bmc_tx_by_bmc: 0 os2bmc_tx_by_host: 0 os2bmc_rx_by_host: 0 rx_errors: 0 tx_errors: 0 tx_dropped: 0 rx_length_errors: 0 rx_over_errors: 0 rx_frame_errors: 0 rx_fifo_errors: 0 tx_fifo_errors: 0 tx_heartbeat_errors: 0 tx_queue_0_packets: 0 tx_queue_0_bytes: 0 tx_queue_0_restart: 0 rx_queue_0_packets: 0 rx_queue_0_bytes: 0 rx_queue_0_drops: 0 rx_queue_0_csum_err: 0 rx_queue_0_alloc_failed: 0
4.5.1.5.2 开启多队列
首先要支持MSI-X (内核2.6.24+)
Linux 网卡驱动一般只有两种 e1000 和 igb. (无线的是iwlagn):
#下面来自 本发行版包括两个适用于英特尔® 网卡的 Linux 基础驱动程序。这两个驱动程序的名称是 e1000 和 igb。为支持任何基于 82575 的网卡,必须安装 igb 驱动程序。其它所有网卡要求 e1000 驱动程序。
先通过lspci看看当前用的是什么驱动:
06:00.2 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)
Subsystem: Intel Corporation I350 Gigabit Network Connection
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin C routed to IRQ 18
Region 0: Memory at a9a20000 (32-bit, non-prefetchable) [size=128K]
Region 2: I/O ports at 1020 [size=32]
Region 3: Memory at a9a84000 (32-bit, non-prefetchable) [size=16K]
Capabilities: <access denied>
Kernel driver in use: igb
Kernel modules: igb
06:00.3 Ethernet controller: Intel Corporation I350 Gigabit Network Connection (rev 01)
Subsystem: Intel Corporation I350 Gigabit Network Connection
Control: I/O+ Mem+ BusMaster+ SpecCycle- MemWINV- VGASnoop- ParErr+ Stepping- SERR- FastB2B- DisINTx+
Status: Cap+ 66MHz- UDF- FastB2B- ParErr- DEVSEL=fast >TAbort- <TAbort- <MAbort- >SERR- <PERR- INTx-
Latency: 0, Cache Line Size: 64 bytes
Interrupt: pin D routed to IRQ 19
Region 0: Memory at a9a00000 (32-bit, non-prefetchable) [size=128K]
Region 2: I/O ports at 1000 [size=32]
Region 3: Memory at a9a80000 (32-bit, non-prefetchable) [size=16K]
Capabilities: <access denied>
Kernel driver in use: igb
Kernel modules: igb
igb是一个内核mod:
$ lsmod | grep igb igb 143886 0
看看这个mod支持啥参数:
$ modinfo igb filename: /lib/modules/2.6.32_1-12-0-0/kernel/drivers/net/igb/igb.ko version: 4.0.17 license: GPL description: Intel(R) Gigabit Ethernet Network Driver author: Intel Corporation, <e1000-devel@lists.sourceforge.net> srcversion: BCB38D2CABB33E0A1BA8385 ... depends: vermagic: 2.6.32_1-12-0-0 SMP mod_unload modversions parm: InterruptThrottleRate:Maximum interrupts per second, per vector, (max 100000), default 3=adaptive (array of int) parm: IntMode:Change Interrupt Mode (0=Legacy, 1=MSI, 2=MSI-X), default 2 (array of int) parm: Node:set the starting node to allocate memory on, default -1 (array of int) parm: LLIPort:Low Latency Interrupt TCP Port (0-65535), default 0=off (array of int) parm: LLIPush:Low Latency Interrupt on TCP Push flag (0,1), default 0=off (array of int) parm: LLISize:Low Latency Interrupt on Packet Size (0-1500), default 0=off (array of int) parm: RSS:Number of Receive-Side Scaling Descriptor Queues (0-8), default 1, 0=number of cpus (array of int) parm: VMDQ:Number of Virtual Machine Device Queues: 0-1 = disable, 2-8 enable, default 0 (array of int) parm: max_vfs:Number of Virtual Functions: 0 = disable, 1-7 enable, default 0 (array of int) parm: MDD:Malicious Driver Detection (0/1), default 1 = enabled. Only available when max_vfs is greater than 0 (array of int) parm: QueuePairs:Enable Tx/Rx queue pairs for interrupt handling (0,1), default 1=on (array of int) parm: EEE:Enable/disable on parts that support the feature (array of int) parm: DMAC:Disable or set latency for DMA Coalescing ((0=off, 1000-10000(msec), 250, 500 (usec)) (array of int) parm: LRO:Large Receive Offload (0,1), default 0=off (array of int) parm: debug:Debug level (0=none, ..., 16=all) (int)
通过调整IntMode, RSS, /etc/modules.conf or /etc/modprobe.conf
alias eth0 igb alias eth1 igb options igb IntMode=2,1 RSS=4,4
On some kernels a reboot is required to switch between a single queue mode and multiqueue modes, or vice-versa.
可以看这里的intel驱动文档:
http://downloadmirror.intel.com/20927/eng/e1000.htm
IntMode:
0-2 (0 = Legacy Int, 1 = MSI and 2 = MSI-X)
IntMode controls allow load time control over the type of interrupt registered for by the driver. MSI-X is required for multiple queue support, and some kernels and combinations of kernel .config options will force a lower level of interrupt support. 'cat /proc/interrupts' will show different values for each type of interrupt.
RSS
0-8:
0 - Assign up to whichever is less, number of CPUS or number of queues
X - Assign X queues where X is less than the maximum number of queues
4.5.2 /proc/softirqs
ning@ning-laptop ~/test$ cat /proc/softirqs
CPU0 CPU1 CPU2 CPU3
HI: 185922 155733 322202 415150
TIMER: 116015047 115689110 116242953 114220601
NET_TX: 145507222 2411961 2579050 2645211
NET_RX: 91563132 62827666 54938487 56726882
BLOCK: 12582678 387007 389099 477301
BLOCK_IOPOLL: 39 0 14 1
TASKLET: 268807160 8526283 10469002 7812433
SCHED: 85717988 81576238 76344646 74394437
HRTIMER: 38106 42778 28602 28957
RCU: 110562375 107074305 102180377 98345842
4.5.2.1 mpstat
mpstat [ -P { cpu | ALL } ] [ -V ] [ interval [ count ] ]
CPU
Processor number. The keyword all indicates that statistics are
calculated as averages among all processors.
...
%iowait
Show the percentage of time that the CPU or CPUs were idle dur-
ing which the system had an outstanding disk I/O request.
%irq (有多少时间花在处理中断)
Show the percentage of time spent by the CPU or CPUs to service
interrupts.
%soft
Show the percentage of time spent by the CPU or CPUs to service
softirqs. A softirq (software interrupt) is one of up to 32
enumerated software interrupts which can run on multiple CPUs at
once.
%idle
Show the percentage of time that the CPU or CPUs were idle and
the system did not have an outstanding disk I/O request.
intr/s
Show the total number of interrupts received per second by the
CPU or CPUs.
两种用法:
#看总体情况 mpstat 1 #看每个CPU情况. mpstat -P ALL 1
4.5.2.2 vmstat
$ vmstat 1 procs -----------memory---------- ---swap-- -----io---- --system-- ----cpu---- r b swpd free buff cache si so bi bo in cs us sy id wa 5 0 975864 3730960 237268 30782988 0 0 1 110 0 0 13 7 80 0 1 0 975864 3731720 237268 30783940 0 0 0 412 111381 93381 5 10 85 0 3 0 975864 3731780 237268 30784904 0 0 0 356 110127 92617 5 10 86 0 5 0 975864 3729672 237268 30785796 0 0 0 324 109500 90538 5 9 86 0 system的in这一列, 就是说每秒多少中断.
4.6 Softirqs and Tasklets
TODO: SoftIRQ(软中断) 和中断/异常是什么关系??
ksoftirqd/n 内核线程:
for(;;) {
set_current_state(TASK_INTERRUPTIBLE);
schedule();
/* now in TASK_RUNNING state */
while (local_softirq_pending()) {
preempt_disable();
do_softirq();
preempt_enable();
cond_resched();
}
}
4.7 Work Queues
工作队列实际上是这样一种概念: 硬件中断发生时, 把中断对应的处理函数加到一个队列里面, 再由一个 内核线程 来对这个队列里面的每个函数, 逐一调用, 可以简化中断处理例程.
这种方法和lighttpd对请求有事件来时的处理很像.
预定义的Work Queue: events
内核线程:
- keventd(通用)
- kblockd(块设备层使用)
4.8 Returning from Interrupts and Exceptions
- ret_from_intr(): 中断处理结束时
- ret_from_exception(): 异常处理结束时
5 c5 Kernel Synchronization
5.1 How the Kernel Services Requests
可以把内核看作不断对请求进行响应的服务器, 这些请求可能来自CPU上执行的进程, 也可能来自发出中断请求的外部设备.
5.1.1 内核抢占
- 抢占内核的主要特点是: 一个在内核台运行的进程, 可能在执行内核函数期间被另一个进程取代.
- 比如一个执行异常处理程序的进程, 用完了它的时间片, 如果内核是抢占的, 进程会立即被取代. 如果内核不是抢占的, 进程继续执行直到它执行完异常处理程序或主动放弃CPU.
- 使内核可抢占的目的是: 减少用户态进程的分派延迟.
- 内核抢占会引起不容忽视的开销, 所以2.6内核允许用户在编译的时候设置是否开启内核抢占.
这个界定其实不严格.
5.2 Synchronization Primitives(同步原语)
Table 5-2. Various types of synchronization techniques used by the kernel
| Technique | Description | Scope | |
|---|---|---|---|
| Per-CPU variables | 每CPU变量 | Duplicate a data Structure among the CPUs | All CPUs |
| Atomic operation | 原子操作 | Atomic read-modify-write instruction to a counter | All CPUs |
| Memory barrier | 内存屏障 | Avoid instruction reordering(避免指令重排) | Local CPU or All CPUs |
| Spin lock | 自旋锁 | Lock with busy wait | All CPUs |
| Semaphore | 信号量 | Lock with blocking wait (sleep) | All CPUs |
| Seqlocks | 顺序锁 | Lock based on an access counter | All CPUs |
| Local interrupt disabling | 本地中断禁止 | Forbid interrupt handling on a single CPU | Local CPU |
| Local softirq disabling | 本地软中断禁止 | Forbid deferrable function handling on a single CPU | Local CPU |
| Read-copy-update (RCU) | 通过指针而不是锁 | Lock-free access to shared data structures through pointers | All CPUs |
RCU 应该是指一些无锁数据结构操作方式,
Read-copy-update 这个术语是针对 读-修改-写(read-modify-write) 这种常见的操作模式来说的.
5.2.1 每CPU变量
各个CPU的数据在硬件Cache中, 保证不会存放在同一个 Cache Line, 对每CPU数组的并发访问不会导致Cache Line的窃用和失效.
使用:
DEFINE_PER_CPU(type, name) Statically allocates a per-CPU array called name of type data structures per_cpu(name, cpu) Selects the element for CPU cpu of the per-CPU array name
每个CPU的运行队列就是 每CPU变量
5.2.2 原子操作
哪些操作是原子的 :
- 进行0次或1次 对齐 内存访问的汇编指令(如int/指针赋值) 但是要注意, 对齐 很重要, 一个结构体中, 很容易不对齐, 静态堆/栈/malloc是否对齐 依赖编译器.
- 如果读操作后, 写操作前没有其它处理器占用内存总线(如 inc , dec )
- 操作码有lock前缀(控制单元此时锁定内存总线, 直到这条指令执行完成)
注意 : C代码中, 不能保证编译器会将 a=a+1 甚至 a++ 这样的操作使用一个原子指令 (但是赋值是)
原子操作:
atomic_read(v) atomic_set(v) atomic_add(v) atomic_add_return(v)
5.2.3 优化屏障&内存屏障
CPU的多发射会导致指令重排, 如果放在同步原语之后的一条指令在同步原语之前执行, 就悲剧了.
5.2.3.1 优化屏障(optimization barrier) 原语保证编译程序不会混淆原语前后的汇编指令.
Linux中, 优化屏障:
barrier()
展开为:
asm volatile("":::"memory")
优化屏障 并不保证不使当前CPU把汇编指令混在一起执行. -- 这是 内存屏障 的作用
5.2.3.2 内存屏障确保原语之后的操作开始执行之前, 原语之前的操作已完成.
在80x86处理器中, 下列种类的汇编指令是串行的, 他们起到 内存屏障 的作用:
对I/O端口操作的所有指令
lock前缀的所有指令
写控制寄存器, 系统寄存器或调试寄存器的指令(cli, sti)
- Pentium 4中引入的
- lfence: 读内存屏障, 仅作用于读内存的指令
- sfence: 写内存屏障, 仅作用于写内存的指令
- mfence: 读-写内存屏障.
少数汇编指令, 如iret.
Linux使用6个内存屏障原语, 它们同时也被作为优化屏障:
mb() Memory barrier for MP and UP rmb() Read memory barrier for MP and UP wmb() Write memory barrier for MP and UP smp_mb() Memory barrier for MP only smp_rmb() Read memory barrier for MP only smp_wmb() Write memory barrier for MP only
rmb 可能展开为:
asm volatile("lfence")
asm volatile("lock;addl $0,0(%%esp)":::"memory")
lock; addl $0,0(%%esp)
wmb可能展开为:
barrier()
5.2.4 自旋锁
锁里面最简单的一种, 忙等锁.
很多自旋锁只会锁1ms时间, 所以, 自旋锁不会造成很大的浪费.
spin_lock_init() Set the spin lock to 1 (unlocked) spin_lock() Cycle until spin lock becomes 1 (unlocked), then set it to 0 (locked) spin_unlock() Set the spin lock to 1 (unlocked) spin_unlock_wait() Wait until the spin lock becomes 1 (unlocked) spin_is_locked() Return 0 if the spin lock is set to 1 (unlocked); 1 otherwise spin_trylock() Set the spin lock to 0 (locked), and return 1 if the previous value of the lock was 1; 0 oth- erwise
5.2.6 顺序锁
SeqLock, 它和读写自旋锁很像, 只是它赋予写者更高的优先级,
即使有读者正在读, 也允许写者继续写,
- 这种策略的好处是写者永远不会等待(除非有另一个写者正在写),
- 缺点是读者必须反复读相同的数据, 直到它获得有效的副本.
每个读者在读前后两次读 顺序计数器 , 如果两次读到的值不相同, 说明新的写者已经开始写并增加了 顺序计数器
p237, 在内核更新Time的时候使用了顺序锁, 这时读者其实可以只读一次, 因为取到旧时间关系不大.
5.2.7 读-拷贝-更新 (RCU通过指针而不是锁)
不用锁:
- RCU只保护被动态分配 通过指针引用的数据结构
读者几乎不做任何事情来防止竞争条件, 得靠写者.
写着要更新数据结构时, 生成整个数据结构的副本, 写者修改这个副本, 修改完成后改变指针.
改变指针是一个原子操作(我们在cruiser中需要动态加载配置的时候就是这样做的)
写着修改指针后, 不能马上释放数据结构的旧副本, 因为写着修改时, 可能有读者拿着老指针呢.!!! --从前自己改这个模块的时候根本没意识到, 只是模仿了浩哥的代码
5.2.8 信号量
类似于自旋锁, 但是在锁的时候不是自旋, 而是挂起.
信号量结构:
struct semphore{
atomic_t count;
wait: 等待队列
sleepers: 是否有进程在信号量上睡眠
}
__up 和 __down
5.2.8.1 补充原语(completion)
类似信号量,
6 c6 Timing Measurements
6.1 Clock and Timer Circuits (几种硬件计时器)
- 实时时钟 RTC (CMOS时间 )
- 和CMOS在一个芯片上, 自带电池
- 频率在2-8192Hz之间.
- IRQ8
- 时间戳计数器 TSC
- 64位
- 每个时钟信号来加1
- 可编程间隔定时器 PIT (8254芯片)
- Linux编程为 大约 1000Hz, 向IRQ0发中断.
CPU本地定时器
- 高精度事件定时器 HPET
- 8个32/64位独立计数器, 硬件中还不普遍.
PCPI电源管理定时器
内核启动时会选择最好的一个计时器
6.2 The Linux Timekeeping Architecture
内核使用两个函数:
time() gettimeofday()
数据结构:
- timer_opts
- 描述硬件定时器(每种硬件一个这个结构)
- jiffies
- 每个时钟中断加一, 内核就是设置为1000Hz
- 80x86中是32位, (2**32/80000*1000)大约50天回绕到0, 内核处理了溢出.
- jiffies 被初始化为0xfffb6c20(-300,000) 系统启动5分钟后回到0(使得哪些不对jiffies做校验的bug及早发现)
- jiffies通过连接器被转换为一个64为计数器的低32位, 这个64位计数器: jiffies_64
- xtime (timespec类型 )
- tv_sec (timestamp的秒数)
- tv_nsec (纳秒)
- 初始化时用get_coms_time() 函数从 实时时钟读取.
6.2.1 时钟中断时处理
- 需要判断是否丢失时钟中断.
- 计算当前系统的负载(Load)
- 更新xtime
6.2.1.2 监管内核代码
6.2.1.2.1 readprofiler, 用于确定内核热点(hot spot).
监管器基于非常简单的 蒙特卡洛算法, 每次时钟中断发生时, 内核确定中断是否发生在内核态, 如果是, 内核从堆栈取出eip寄存器值, 从而确定中断发生前内核正在做什么. 形成采样数据.
启动内核时需要用 profile=N来开启prifile
数据可以从 /proc/profile 读取, 用 readprofile 命令更方便
6.2.1.2.2 oprofile
此外, 内核提供另一个监管器: oprofile, 还可一监控用户态程序热点.
6.2.1.2.3 检测死锁
通过非屏蔽中断NMI.
6.2.1.2.4 蒙特卡洛:
蒙特卡罗方法又称统计模拟法、随机抽样技术,是一种随机模拟方法,以概率和统计理论方法为基础的一种计算方法,是使用随机数(或更常见的伪随机数)来解决很多计算问题的方法。
这个词构忽悠,其实就是随机采样的意思.
提出:
蒙特卡罗方法于20世纪40年代美国在第二次世界大战中研制原子弹的“曼哈顿计划”计划的成员S.M.乌拉姆和J.冯·诺伊曼首先提出。数学家冯·诺伊曼用驰名世界的赌城—摩纳哥的Monte Carlo—来命名这种方法,为它蒙上了一层神秘色彩。在这之前,蒙特卡罗方法就已经存在。1777年,法国数学家布丰(Georges Louis Leclere de Buffon,1707—1788)提出用投针实验的方法求圆周率π。这被认为是蒙特卡罗方法的起源。
7 c7 Process Scheduling
亲和性:
sched_setaffinity() sched_getaffinity()
7.3 Data Structures Used by the Scheduler
140个双向链表, 代表140个优先级,
7.4 Functions Used by the Scheduler(schedule)
schedule 执行的前半部分和后半部分在两个进程中, 中间还有一段时间不属于任何一个进程.
7.5 多处理器系统中 执行队列的平衡
Linux 一直使用对称多处理器模型(), 内核不应该对任何一个CPU有偏好(有点分布式系统中无master的意思)
- 超线程:
- 当前线程在访问内存的间隙, 处理器可以利用机器周期去执行另外一个线程,
- 一个超线程的物理CPU可以被linux看作是几个逻辑CPU
- NUMA
- 把CPU和RAM以本地节点为单位分组(通常一个节点包括一个CPU和几个RAM芯片)
- CPU访问本地RAM非常快, 防伪其它节点就非常慢.
一般来说, 一个进程总是在一个CPU上执行, 但是也会在CPU之间迁移.
任何一个可运行的进程都不会同时出现在两个或多个CPU的运行队列中, 一个保持可运行状态的进程通常被限制在一个固定的CPU上.
内核周期性的检查运行队列是否平衡, 必要时迁移.
8 c8 Memory Management
8.1 Page Frame Management
页描述符大小为32字节(放在mem_map中), 用于描述一个4k大小的页, 所以内存的(32/4k=0.8%) 的内存用于存放页描述符(被内核使用)
8.1.1 非一致内存访问(NUMA)
Non-Uniform Memory Access, 对比与80x86体系结构的UMA模型(一致性内存访问)
NUMA中, 某个CPU对不同内存单元的访问时间可能不一样, 系统中的CPU和内存被划分为几个节点. 一个节点内的cpu访问自己节点的内存很快, 跨节点访问就很慢.
8.2 Memory Area Management
slab分配器: 类似于 预分配/对象池 的概念
- 把内存去看作对象, 有构造/析构函数.
- 内核反复申请同一类型的内存区.
slab着色 - 解决高速缓存颠簸的问题.
21 总结
- 其实中文版翻译还算可以, 中文看不懂的地方, 去看英文版, 发现一样看不懂.
- 不过看英文版映像深一些.
- 读这本书, 需要和源码一起看
- 比如c2 内存寻址 里面详细列出了页表操作的宏定义, 读的时候就每必要细究.
- 之前一致理解有内核和用户进程这两种东西
实际上, 应该是一个进程, 可以运行在用户态, 也可以运行在内核态
当发起系统调用的时候, 进入内核态, 切换栈为内核栈,
- 用户态只能访问本进程的部分线性地址空间.
- 进入内核态后, 可以访问全部线性地址空间.
还有一些进程是只在内核态运行的
- 内核在运行中的代码形态(CPU执行内核代码的时候)
- 初始化系统
- 普通进程调用系统调用, 进入内核态, 用该进程的内核堆栈执行.
- 几个内核线程
- 中断处理
- c5 Kernel Synchronization
- 对各种锁的介绍挺全面.
- 自旋锁是锁里面最简单的一种,
- 信号量是自旋锁的一种改进
对内存屏障的介绍, 看一遍就懂了