twemproxy-benchmark
1 问题
在我们用 redis-mgr 部署的集群里面, 使用 benchmark测试:
以比较典型的部署:
4台机器,
每台机器2个redis-master, 2个nutcracker:
'redis': [
('m-01:2200', '/home/ning/redis-sandbox2/redis-2200'), ('m-02:3200', '/home/ning/redis-sandbox2/redis-3200'),
('m-01:2201', '/home/ning/redis-sandbox2/redis-2201'), ('m-02:3201', '/home/ning/redis-sandbox2/redis-3201'),
('m-02:2202', '/home/ning/redis-sandbox2/redis-2202'), ('m-03:3202', '/home/ning/redis-sandbox2/redis-3202'),
('m-02:2203', '/home/ning/redis-sandbox2/redis-2203'), ('m-03:3203', '/home/ning/redis-sandbox2/redis-3203'),
('m-03:2204', '/home/ning/redis-sandbox2/redis-2204'), ('m-04:3204', '/home/ning/redis-sandbox2/redis-3204'),
('m-03:2205', '/home/ning/redis-sandbox2/redis-2205'), ('m-04:3205', '/home/ning/redis-sandbox2/redis-3205'),
('m-04:2206', '/home/ning/redis-sandbox2/redis-2206'), ('m-01:3206', '/home/ning/redis-sandbox2/redis-3206'),
('m-04:2207', '/home/ning/redis-sandbox2/redis-2207'), ('m-01:3207', '/home/ning/redis-sandbox2/redis-3207'),
],
'nutcracker': [
('m-01:4200', '/home/ning/redis-sandbox2/nutcracker-4200'),
('m-01:4201', '/home/ning/redis-sandbox2/nutcracker-4201'),
('m-02:4200', '/home/ning/redis-sandbox2/nutcracker-4200'),
('m-02:4201', '/home/ning/redis-sandbox2/nutcracker-4201'),
('m-03:4200', '/home/ning/redis-sandbox2/nutcracker-4200'),
('m-03:4201', '/home/ning/redis-sandbox2/nutcracker-4201'),
('m-04:4200', '/home/ning/redis-sandbox2/nutcracker-4200'),
('m-04:4201', '/home/ning/redis-sandbox2/nutcracker-4201'),
],
使用如下benchmark:
$ ./bin/deploy.py cluster_sandbox2 nbench 1000000 2014-02-10 16:15:52,758 [MainThread] [INFO] start running: ./bin/deploy.py -v cluster_sandbox2 nbench 1000000 2014-02-10 16:15:52,783 [Thread-1] [INFO] ssh -n -f ning@10.65.19.52 "cd /home/ning/redis-sandbox2/redis-2200 && bin/redis-benchmark --csv -h 10.65.19.52 -p 4200 -r 100000 -t set,get -n 1000000 -c 100 " 2014-02-10 16:15:52,799 [Thread-2] [INFO] ssh -n -f ning@10.65.19.26 "cd /home/ning/redis-sandbox2/redis-2202 && bin/redis-benchmark --csv -h 10.65.19.52 -p 4201 -r 100000 -t set,get -n 1000000 -c 100 " 2014-02-10 16:15:52,814 [Thread-3] [INFO] ssh -n -f ning@10.65.19.52 "cd /home/ning/redis-sandbox2/redis-2200 && bin/redis-benchmark --csv -h 10.65.19.26 -p 4200 -r 100000 -t set,get -n 1000000 -c 100 " 2014-02-10 16:15:52,831 [Thread-4] [INFO] ssh -n -f ning@10.65.19.52 "cd /home/ning/redis-sandbox2/redis-2201 && bin/redis-benchmark --csv -h 10.65.19.26 -p 4201 -r 100000 -t set,get -n 1000000 -c 100 " 2014-02-10 16:15:52,843 [Thread-5] [INFO] ssh -n -f ning@10.65.19.52 "cd /home/ning/redis-sandbox2/redis-2201 && bin/redis-benchmark --csv -h 10.65.19.27 -p 4200 -r 100000 -t set,get -n 1000000 -c 100 " 2014-02-10 16:15:52,855 [Thread-6] [INFO] ssh -n -f ning@10.65.19.26 "cd /home/ning/redis-sandbox2/redis-2202 && bin/redis-benchmark --csv -h 10.65.19.27 -p 4201 -r 100000 -t set,get -n 1000000 -c 100 " 2014-02-10 16:15:52,870 [Thread-7] [INFO] ssh -n -f ning@10.65.19.26 "cd /home/ning/redis-sandbox2/redis-2203 && bin/redis-benchmark --csv -h 10.65.15.234 -p 4200 -r 100000 -t set,get -n 1000000 -c 100 " 2014-02-10 16:15:52,887 [Thread-8] [INFO] ssh -n -f ning@10.65.19.52 "cd /home/ning/redis-sandbox2/redis-2201 && bin/redis-benchmark --csv -h 10.65.15.234 -p 4201 -r 100000 -t set,get -n 1000000 -c 100 "
想当于起8个worker, 随机登录到这4台机器上, 用redis-benchmark向随机一个nutcracker 发:
bin/redis-benchmark --csv -h 10.65.19.52 -p 4200 -r 100000 -t set,get -n 1000000 -c 100
实际效果, 从redis-master 观察到的 qps 如下:
_2200 2201 2202 2203 2204 2205 2206 2207 31070 31187 31330 31143 31129 30843 30561 31198 16:10:27 28709 28226 28184 28054 27960 27934 27763 28227 16:10:28 28039 28104 28076 28148 28140 28065 28108 28429 16:10:29 28060 28026 27791 27938 28006 27968 27901 28236 16:10:31 27277 27314 27120 26693 27308 26892 26961 27100 16:10:32
这些redis-benchmark跑完结果如下:
Warning: Permanently added '10.65.19.26' (RSA) to the list of known hosts. "SET","32128.51" "GET","32101.70" Warning: Permanently added '10.65.19.26' (RSA) to the list of known hosts. "SET","28050.49" "GET","37503.75"
此时目标机器上nutcracker进程占cpu 50%左右
总的来说, 单个redis实例, qps只能到2.5w左右, 并不能发挥全部潜力
如果直接向redis-master 发benchmark:
./bin/deploy.py cluster_sandbox2 mbench 1000000 _2200 2201 2202 2203 2204 2205 2206 2207 65403 52966 72511 59942 56849 67403 73925 73807 16:14:29 59207 59013 72661 59847 62023 70425 73797 73419 16:14:30 61209 64150 72458 59782 61011 71315 73880 57140 16:14:31 61558 69808 63582 57293 58958 71804 73205 70450 16:14:32 61728 70484 60712 61016 58986 64976 73757 73305 16:14:33 Warning: Permanently added '10.65.19.26' (RSA) to the list of known hosts. "SET","63123.34" "GET","72854.44"
看到每个redis实例的qps约7w/s.
为什么经过了一个nutcracker, pqs就从 7w下降到2.5w呢?
2 过程
试试单个benchmark进程:
ssh -n -f ning@10.65.19.52 "cd /home/ning/redis-sandbox2/redis-2200 && bin/redis-benchmark --csv -h 10.65.19.52 -p 4200 -r 100000 -t set,get -n 1000000 -c 100 " "SET","70185.29" "GET","67449.08" 每个master上的压力大约9k, 总压力能到7w左右 2200 2201 2202 2203 2204 2205 2206 2207 9320 9233 9144 9256 9128 9191 9296 9239 16:19:56
能到7w左右, 是没有问题的, 此时目标机器上nutcracker进程占cpu 90%-99%.
发现问题, 用自己的nbench命令, 是随机选择一个机器作为压力发起的机器, 存在很大的不均匀现象:
ssh -n -f ning@10.65.19.52 ssh -n -f ning@10.65.19.52 ssh -n -f ning@10.65.19.52 ssh -n -f ning@10.65.19.52 ssh -n -f ning@10.65.19.52 ssh -n -f ning@10.65.19.26 ssh -n -f ning@10.65.19.26 ssh -n -f ning@10.65.19.26
因为每台机器上有4个redis, 2个proxy, 再开2个benchmark 进程, 就会打满8个核(总共就8个核)
如果有3个benchmark进程在同一个机器上, 多余的benchmark进程的压力就上不来 (benchmark进程也占87%左右的cpu)
原来发benchmark的任务实现:
def nbench(self, cnt=100000):
'''
run benchmark against nutcracker
'''
for s in self.all_nutcracker:
args = copy.deepcopy(s.args)
args['cnt'] = cnt
cmd = TT('bin/redis-benchmark --csv -h $host -p $port -r 100000 -t set,get -n $cnt -c 100 ', args)
BenchThread(random.choice(self._active_masters()), cmd).start()
修改了一下:
def nbench(self, cnt=100000):
'''
run benchmark against nutcracker
'''
i = 0
masters= self._active_masters()
for s in self.all_nutcracker:
args = copy.deepcopy(s.args)
args['cnt'] = cnt
cmd = TT('bin/redis-benchmark --csv -h $host -p $port -r 100000 -t set,get -n $cnt -c 100 ', args)
BenchThread(masters[i], cmd).start()
i += 1
i %= len(masters)
保证均匀的在各个机器上起benchmark进程, 就能得到很高的qps, 和直连差别已经很小:
_2200 2201 2202 2203 2204 2205 2206 2207 63227 62220 63270 63240 61574 62673 62855 62078 16:43:34 63889 64202 64157 63754 63181 63986 64152 64234 16:43:35 66386 66852 66858 66445 66835 66672 66700 67084 16:43:36
此时几个核的压力分布:
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 14903 ning 16 0 18928 1908 708 R 90.4 0.0 6:05.93 nutcracker 14865 ning 16 0 22328 2968 712 R 88.8 0.0 10:53.54 nutcracker 517 ning 16 0 22924 6432 680 S 87.8 0.0 0:09.84 redis-benchmark 519 ning 16 0 22924 6136 680 R 87.1 0.0 0:09.33 redis-benchmark 30753 ning 16 0 118m 82m 1116 S 70.9 0.1 18:31.10 redis-server 10746 ning 16 0 126m 87m 1112 R 70.0 0.1 13:40.51 redis-server 21287 ning 16 0 52196 17m 1132 R 38.6 0.0 12:24.57 redis-server 28560 ning 16 0 55420 17m 1240 R 37.0 0.0 17:27.72 redis-server
可以看出, 满负荷的时候, nutcracker占满cpu, benchmark也很消耗cpu,
3 结论
- 看到的nutcracker导致集群性能下降, 其实是自己的benchmark方法不合理, 客户端性能受限导致
- 如果在cpu很空闲的机器上发benchmark, qps应该更高.
4 具体性能分析
火焰图:
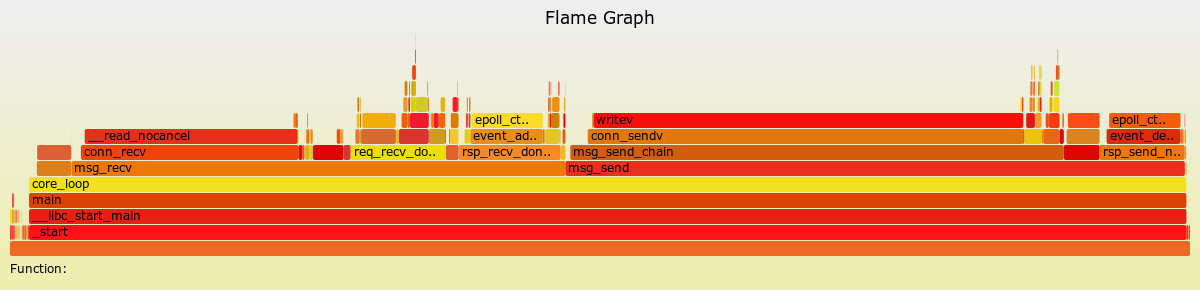
{kind=link}
可以看出:
- 程序逻辑:
- event_wait
- msg_recv
- msg_send
conn_recv: 18.4% , conn_sendv 36.9% 这基本等于调用系统调用read/write 的时间 总共占 55%. 这一部分时间是不可能被优化的了
event_add_out, event_del_out, 下面都是epoll_ctl, 在不同场景下调用, 大约有4种情况, 占用时间18%左右
event_wait 占用 2.9%
redis_parse_req 2.6%
parse_req, 队列的enqueue, dequeue 操作合起来占5%左右.
其它
可优化的空间较小了.