ssdb-benchmark
Table of Contents
因为小规模benchmark时文件都被cache, IO访问其实只有内存操作而已, 所以测试数据只能说明系统在基本无IO操作时的处理能力.
为了避免文件被cache, 可以减少机器空闲内存, 或者使操作的数据集远大于内存, 我们的测试机内存64G, 所以测试时, 我们使用大约100G的数据集来进行测试.
benchmark场景:
先写, 后读, 采集的数据包括:
- qps随时间的变化
- 进程内存, cpu占用,
- 磁盘读写带宽, r/s, w/s, await, %util,
- 磁盘占用量.
为此, 写了这样一个程序用于benchmark和记录结果:
...
class LoadThread(threading.Thread):
def run(self):
global g_qps
num = 1000000000
#num = 100000
cmd = 'redis-benchmark -p 8888 -t set -n %s -r 100000000000 -d 100' % num
p = Popen(cmd, shell=True, stdout=PIPE, bufsize=1024)
for line in iter(lambda: p.stdout.readline(), ''):
line = str(line).strip()
#print(">>> " + line)
if line.startswith('SET'):
g_qps = line.split()[1]
cmd = 'redis-benchmark -p 8888 -t get -n %s -r 100000000000 -d 100' % num
p = Popen(cmd, shell=True, stdout=PIPE, bufsize=1024)
for line in iter(lambda: p.stdout.readline(), ''):
line = str(line).strip()
#print(">>> " + line)
if line.startswith('GET'):
g_qps = line.split()[1]
...
代码在此: https://github.com/idning/iostat-py/blob/master/ssdb-bench/ssdb-bench.py
1 hdd 测试结果
这个测试是手工完成和记录的, 没有图.
写:
$ redis-benchmark -p 8888 -t set -n 1000000000 -r 100000000000 -d 100 38000
持续写1000000000条, (93G)
磁盘写带宽持续70M/s左右, 内存使用会上升到10G左右, 低峰会回落, 12核cpu上, cpu占用约30%(4个核占满)
qps稳定在3.8w/s, 不会随着写数据增多而变差.
写完之后, 读:
$ redis-benchmark -p 8888 -t get -n 1000000000 -r 100000000000 -d 100 60~400
如果能命中热点:
$ redis-benchmark -p 8888 -t get -n 1000000000 -r 100000 -d 100 23803.46
初始qps只能达到60/s, 逐渐上升到400/s趋于稳定.
此时磁盘每秒读请求达到150-300r/s (达到磁盘IOPS极限):
Device: rrqm/s wrqm/s r/s w/s rkB/s wkB/s avgrq-sz avgqu-sz await svctm %util sda 0.00 0.00 137.00 0.00 12940.00 0.00 188.91 1.08 7.86 6.86 94.00
小结:
ssdb在hdd上的表现:
- 写性能稳定在40000/s左右. 不随着数据集的增大而变差.
- 读性能在不能命中热点的情况下, 受限于磁盘的IOPS (400/s)
hdd上, ssdb适合写多读少的场景.
2 ssd 测试结果
环境:
/dev/sdb1 on /ssd type ext4 (rw,noatime) mem: 48G cpu: 12 ssd: Intel SSD 530 480GB, 2.5in SATA 参数: http://ark.intel.com/products/75336/Intel-SSD-530-Series-480GB-2_5in-SATA-6Gbs-20nm-MLC
这块SSD 的性能参数:
- Random Read : 48000 IOPS
- Random Write : 80000 IOPS
我们实际上是3块ssd做RAID0, fio测试结果:
$ sudo fio -filename=/dev/sdb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=1k -size=200G -numjobs=30 -runtime=1000 -group_repor 5.7w/s $rw=randread 7.3w/s
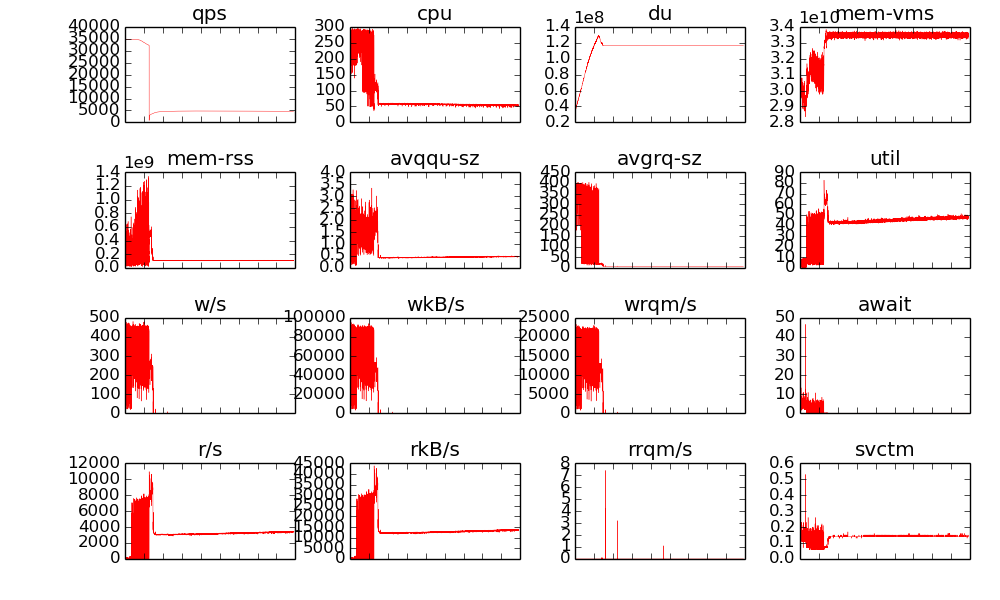
ssdb测试结果:
小结
- ssd上写性能稳定在3.8wqps, 不会随着写数据增多而变差, 和hdd差不多,
- 读性能稳定在5000qps, 明显好与hdd.
- 读性能不够, 只能到5000qps, 而此时ssd上的iops大约 5000-7000/s, 此时util%只能到50%, cpu利用率也上不去, 这里可以优化.
3 LevelDB的问题
LevelDB只有block级别的cache, 所有Key集合是记录在磁盘上, 内存中并没有一个记录key是否存在的hash表或树结构, 所以每次查询, 不管key是否存在, LevelDB都需要到磁盘上去找, 如果block不在缓存中, 就要一层层去找, 是非常耗时的,
为此, LevelDB增加了bloomfilter支持, 可以过滤掉一些key不存在的情况, 减少对磁盘的访问:
ssdb->options.filter_policy = leveldb::NewBloomFilterPolicy(10); ssdb->options.block_cache = leveldb::NewLRUCache(cache_size * 1048576);
4 关于读性能
benchmark显示 100G数据 时, 读性能稳定在大约5000 qps
- 自己实现了一个单线程的服务ndb对比, 发现读qps存在和SSDB一样的低效问题, 而且更低(2000), 如下图:
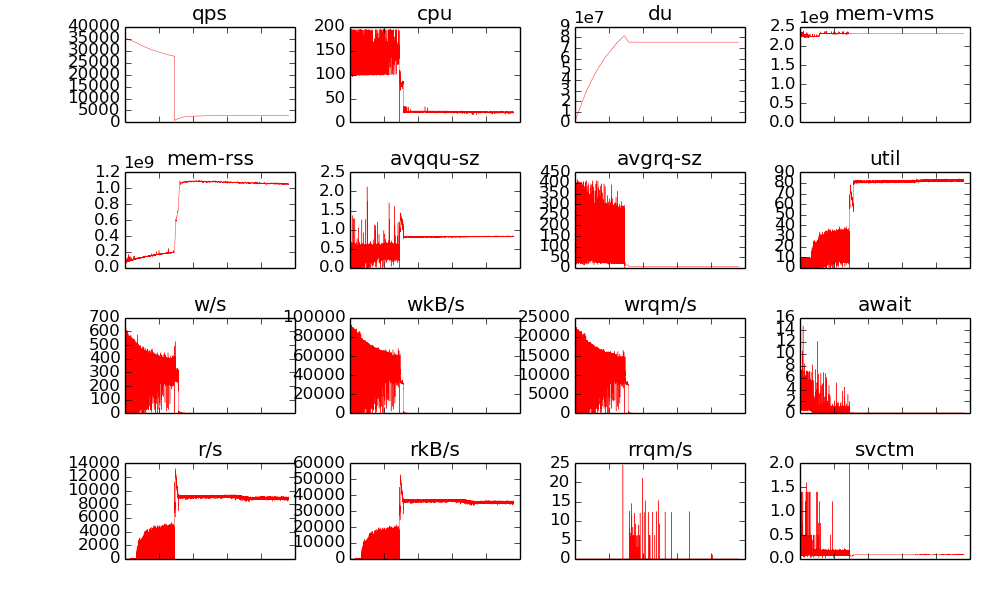
原因:
- ssdb读的时候并未判断expire, 一个读操作只需要一次LevelDB查询, 所以性能较ndb高.
- ssdb是使用单线程去读(并且没有加锁), IO队列上一次只有一个IO请求, 此时avgqu-sz是0.5, 这样想当于把IO操作串行化了, 根据ssd的基本数据, 平均读延迟是90us左右, 也就是说串行使用最多之能支持 1w/s的读操作, 这和我们测的数据比较接近了. 多线程的读操作应该有利于更好的利用io调度器(几个io请求可以排队, 一起发给磁盘控制器)
4.1 改进
修改:
static Command commands[] = {
- PROC(get, "r"),
+ PROC(get, "rt"),
把读放到多线程里面去做, 性能从5000提到15000 , 磁盘r/s 达到23000左右, 日志级别改为error后可以达到16000/s
读没有用Transaction加锁, 所以这时候已经能同时向IO系统发多个IO请求了:
int SSDB::get(const Bytes &key, std::string *val) const{
std::string buf = encode_kv_key(key);
leveldb::Status s = db->Get(leveldb::ReadOptions(), buf, val);
...
return 1;
}
调整 READER_THREADS = 10 为5, 20, 50, 发现在我的机器上10貌似是个最佳值,
4.2 注意
coding for ssd 系列 关于多线程read的观点:
- concurrent read threads can impair the readahead (prefetching buffer) capabilities of SSDs
- A single large read is better than many small concurrent reads Concurrent random reads cannot fully make use of the readahead mechanism. In addition, multiple Logical Block Addresses may end up on the same chip, not taking advantage or of the internal parallelism.
http://codecapsule.com/2014/02/12/coding-for-ssds-part-5-access-patterns-and-system-optimizations/