fatcache-cr
Table of Contents
1 设计理念
- Eliminate small, random disk writes
- batched write
- 如果用mmap的方式使用ssd(比如mongo), 就会产生很多随机写.
- Minimize disk reads on cache hit
- Fatcache reduces disk reads by maintaining an in-memory index for all on-disk data.
- no disk accesses on cache miss and only a single disk access on cache hit.
定期gc, 对所有在磁盘上, 而不在内存索引中的元素清掉.
- 内存index
- 所有key放在内存中, 内存中hash表记录value在磁盘上的位置.
- 拉链式hash表
- 为了减少key放在内存中的大小, 使用sha1, (冲突在读的时候会检测, 写的时候覆盖.)
- The index entry (struct itemx) on a 64-bit system is 44 bytes in size
2 代码
量不大:
ning@ning-laptop ~/idning-github/fatcache/src$ cat *.c *.h|wc -l 9830
util:
fc_queue.h fc_array.c fc_array.h fc_log.c fc_log.h fc_sha1.c fc_sha1.h fc_signal.c fc_signal.h fc_string.c fc_string.h fc_time.c fc_time.h fc_util.c fc_util.h
事件和连接处理:
fc_event.c fc_event.h fc_connection.c fc_connection.h fc_mbuf.c fc_mbuf.h fc_core.c fc_core.h fc_client.c fc_client.h fc_server.c fc_server.h
请求处理:
fc.c fc_memcache.c 协议解析. fc_memcache.h fc_message.c fc_message.h fc_request.c #处理请求, 转化为itemx/slab 存储. 读取. fc_response.c #如何发送response
cache模型:
fc_item.c fc_item.h fc_itemx.c fc_itemx.h fc_slab.c fc_slab.h
util 和 事件处理 部分和twemproxy有极大复用度. 请求处理部分主要是协议的解析.
fc_request是负责将解析出来的请求转化为存储层的函数调用(操作item/itemx/slab)
概念:
- item: 一个kv对,
- itemx: 索引项
- slab: 用来存储item, 一个slab默认是1M(最大可配为512M), 可以存放多个item. slab有内存和磁盘两种类型.
item:
struct item {
uint32_t magic; /* item magic (const) */
uint32_t offset; /* raw offset from owner slab base (const) */
uint32_t sid; /* slab id (const) */
uint8_t cid; /* slab class id (const) */
uint8_t unused[2]; /* unused */
uint8_t nkey; /* key length */
uint32_t ndata; /* date length */
rel_time_t expiry; /* expiry in secs */
uint32_t flags; /* flags opaque to the server */
uint8_t md[20]; /* key sha1*/
uint32_t hash; /* key hash */
uint8_t end[1]; /* item data */
};
uint8_t * item_key(struct item *it) { return it->end; } //获得item->key
uint8_t * item_data(struct item *it) { return it->end + it->nkey; } //获得item->value
size_t item_ntotal(uint8_t nkey, uint32_t ndata) { return ITEM_HDR_SIZE + nkey + ndata; } //获得item大小.
struct itemx {
STAILQ_ENTRY(itemx) tqe; /* link in index / free q */
uint8_t md[20]; /* sha1 */
uint32_t sid; /* owner slab id */
uint32_t offset; /* item offset from owner slab base */
uint64_t cas; /* cas */
} __attribute__ ((__packed__));
struct slab {
uint32_t magic; /* slab magic (const) */
uint32_t sid; /* slab id */
uint8_t cid; /* slab class id */
uint8_t unused[3]; /* unused */
uint8_t data[1]; /* opaque data */
};
2.1 fc_request.c 中的请求处理
static void
req_process_get(struct context *ctx, struct conn *conn, struct msg *msg)
{
struct itemx *itx;
struct item *it;
itx = itemx_getx(msg->hash, msg->md);
if (itx == NULL) {
msg_type_t type;
/*
* On a miss, we send a "END\r\n" response, unless the request
* is an intermediate fragment in a fragmented request.
*/
if (msg->frag_id == 0 || msg->last_fragment) {
type = MSG_RSP_END;
} else {
type = MSG_EMPTY;
}
rsp_send_status(ctx, conn, msg, type);
return;
}
/*
* On a hit, we read the item with address [sid, offset] and respond
* with item value if the item hasn't expired yet.
*/
it = slab_read_item(itx->sid, itx->offset);
if (it == NULL) {
rsp_send_error(ctx, conn, msg, MSG_RSP_SERVER_ERROR, errno);
return;
}
if (item_expired(it)) {
rsp_send_status(ctx, conn, msg, MSG_RSP_NOT_FOUND);
return;
}
rsp_send_value(ctx, conn, msg, it, itx->cas);
}
static void
req_process_set(struct context *ctx, struct conn *conn, struct msg *msg)
{
uint8_t *key, nkey, cid;
struct item *it;
key = msg->key_start;
nkey = (uint8_t)(msg->key_end - msg->key_start);
cid = item_slabcid(nkey, msg->vlen);
if (cid == SLABCLASS_INVALID_ID) {
rsp_send_error(ctx, conn, msg, MSG_RSP_CLIENT_ERROR, EINVAL);
return;
}
itemx_removex(msg->hash, msg->md);
it = item_get(key, nkey, cid, msg->vlen, time_reltime(msg->expiry),
msg->flags, msg->md, msg->hash);
if (it == NULL) {
rsp_send_error(ctx, conn, msg, MSG_RSP_SERVER_ERROR, ENOMEM);
return;
}
mbuf_copy_to(&msg->mhdr, msg->value, item_data(it), msg->vlen);
rsp_send_status(ctx, conn, msg, MSG_RSP_STORED);
}
2.2 mmap 的和 MAP_ANONYMOUS
代码中看到下面这种用法, 不理解是什么意思, 于是查了一下:
void *
_fc_mmap(size_t size, const char *name, int line)
{
p = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANONYMOUS,
-1, 0);
}
man:
MAP_ANONYMOUS The mapping is not backed by any file; its contents are initialized to zero. The fd and offset arguments are ignored; however, some implementations require fd to be -1 if MAP_ANONYMOUS (or MAP_ANON) is specified, and portable applications should ensure this. The use of MAP_ANONYMOUS in conjunction with MAP_SHARED is only supported on Linux since kernel 2.4.
mmap 的 MAP_ANONYMOUS 相当于malloc一片内存:
MAP_ANONYMOUS is commonly used for two things on systems that implement it:
- To share a memory region between a parent and a child, as you said. However, it requires that the child does not execve(), since it must have the pointer to the mmap()ed address.
- To simply get memory pages from the kernel. That's how most malloc() implementations work nowadays. (The glibc malloc() uses brk() for small allocations and mmap() with MAP_ANONYMOUS for big ones.)
使用:
itemx_init:
/* init item index memory */
itx = fc_mmap(settings.max_index_memory);
if (itx == NULL) {
return FC_ENOMEM;
}
istart = itx;
iend = itx + n;
slab_init:
/* init nmslab, mstart and mend */
nmslab = MAX(nctable, settings.max_slab_memory / settings.slab_size);
mspace = nmslab * settings.slab_size;
mstart = fc_mmap(mspace);
2.3 如何获取device_size
rstatus_t
fc_device_size(const char *path, size_t *size)
{
fd = open(path, O_RDONLY, 0644);
status = ioctl(fd, BLKGETSIZE64, size);
return FC_OK;
}
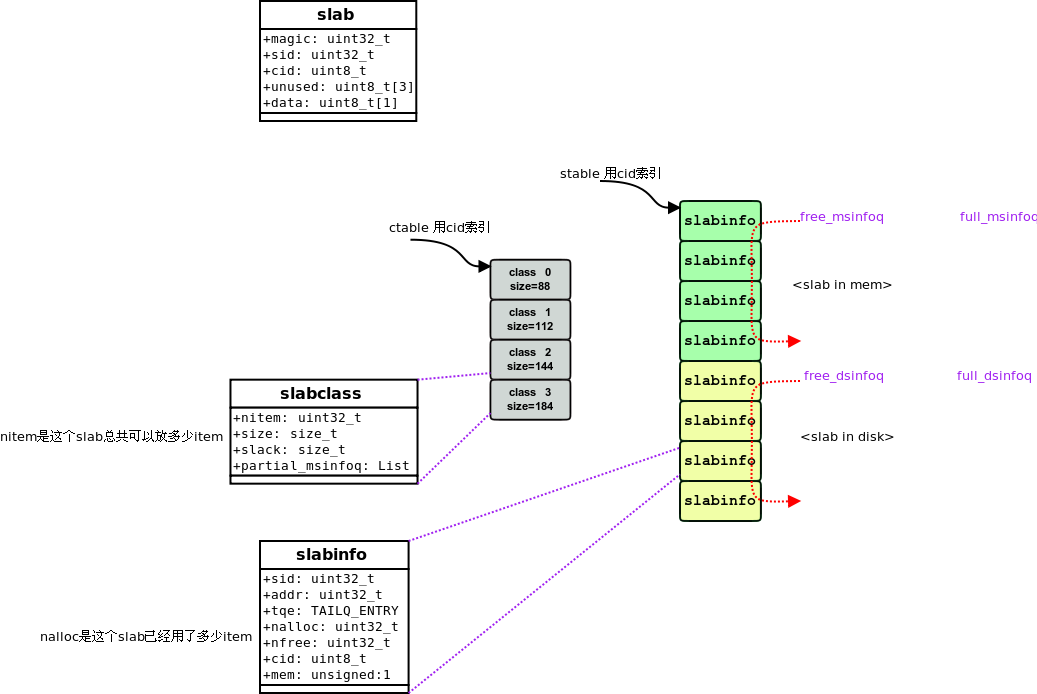
3 slab逻辑
fatcache 有两种slab: mem-slab 和 disk-slab, 大小相同,
mem-slab作为disk-slab的写buffer.
一个slab里面可以包含多个item. 写操作都是写到mem-slab, 写满一个, 就交换到disk-slab, 能做到顺序写, 随机读, 从而最大化ssd利用率.
3.1 启动
struct settings {
size_t max_slab_memory; /* maximum memory allowed for slabs in bytes */
size_t max_index_memory; /* maximum memory allowed for in bytes */
size_t slab_size; /* slab size */
size_t chunk_size; /* minimum item chunk size */
size_t max_chunk_size; /* maximum item chunk size */
double factor; /* item chunk size growth factor */
};
启动后, 先从配置中获得slab_size, 根据配置的mem-slab大小和磁盘大小, 计算总共有多少个slab, 分别初始化 ctable和stable:
slab_init(void)
{
status = slab_init_ctable(); //根据factor, 初始化一系列slab-class, 每个slab-class的item-size呈递增关系.
//计算有多少个mem-slab
nmslab = MAX(nctable, settings.max_slab_memory / settings.slab_size);
//计算有多少个disk-slab
status = fc_device_size(settings.ssd_device, &size);
ndchunk = size / settings.slab_size; //整个device能放多少个slab?
ASSERT(settings.server_n <= ndchunk);
ndslab = ndchunk / settings.server_n;
status = slab_init_stable();
}
slab的总个数就是nmslab+ndslab. slab总数, mslab, dslab 的个数都是不会变的.
初始化完成后, 所有的mem-slab和disk-slab都被标记为free(放到free_xxx_q里面)
初始化完成后, 如下图所示:
3.2 启动日志如下
$ ./src/fatcache -D /dev/sdb -p 11211 -s 0/8 [Wed May 21 21:51:51 2014] fc.c:683 fatcache-0.1.1 started on pid 1721 [Wed May 21 21:51:51 2014] fc.c:688 configured with debug logs disabled, asserts disabled, panic disabled [Wed May 21 21:51:51 2014] fc_slab.c:85 slab size 1048576, slab hdr size 12, item hdr size 52, item chunk size 88 [Wed May 21 21:51:51 2014] fc_slab.c:88 index memory 0, slab memory 67108864, disk space 239498952704 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 0: items 11915 size 88 data 36 slack 44 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 1: items 9362 size 112 data 60 slack 20 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 2: items 7281 size 144 data 92 slack 100 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 3: items 5698 size 184 data 132 slack 132 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 4: items 4519 size 232 data 180 slack 156 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 5: items 3542 size 296 data 244 slack 132 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 6: items 2788 size 376 data 324 slack 276 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 7: items 2221 size 472 data 420 slack 252 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 8: items 1771 size 592 data 540 slack 132 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 9: items 1409 size 744 data 692 slack 268 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 10: items 1120 size 936 data 884 slack 244 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 11: items 891 size 1176 data 1124 slack 748 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 12: items 712 size 1472 data 1420 slack 500 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 13: items 569 size 1840 data 1788 slack 1604 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 14: items 455 size 2304 data 2252 slack 244 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 15: items 364 size 2880 data 2828 slack 244 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 16: items 291 size 3600 data 3548 slack 964 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 17: items 232 size 4504 data 4452 slack 3636 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 18: items 186 size 5632 data 5580 slack 1012 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 19: items 148 size 7040 data 6988 slack 6644 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 20: items 119 size 8800 data 8748 slack 1364 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 21: items 95 size 11000 data 10948 slack 3564 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 22: items 76 size 13752 data 13700 slack 3412 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 23: items 60 size 17192 data 17140 slack 17044 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 24: items 48 size 21496 data 21444 slack 16756 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 25: items 39 size 26872 data 26820 slack 556 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 26: items 31 size 33592 data 33540 slack 7212 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 27: items 24 size 41992 data 41940 slack 40756 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 28: items 19 size 52496 data 52444 slack 51140 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 29: items 15 size 65624 data 65572 slack 64204 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 30: items 12 size 82032 data 81980 slack 64180 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 31: items 10 size 102544 data 102492 slack 23124 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 32: items 8 size 128184 data 128132 slack 23092 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 33: items 6 size 160232 data 160180 slack 87172 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 34: items 5 size 200296 data 200244 slack 47084 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 35: items 4 size 250376 data 250324 slack 47060 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 36: items 3 size 312976 data 312924 slack 109636 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 37: items 2 size 391224 data 391172 slack 266116 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 38: items 2 size 489032 data 488980 slack 70500 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 40: items 1 size 764120 data 764068 slack 284444 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 41: items 1 size 955152 data 955100 slack 93412 [Wed May 21 21:51:51 2014] fc_slab.c:94 class 42: items 1 size 1048564 data 1048512 slack 0
3.3 写操作过程中对slab的使用
req_process_set
cid = item_slabcid(nkey, msg->vlen) //计算需要一个多大的item
itemx_removex(msg->hash, msg->md); //如果索引里面已有, 删掉
item_get //获得一个klen+vlen大小的item.
slab_get_item
1. 尝试从ctable[cid]->partial_msinfoq 里面获取. 如果获取到则返回
2. 尝试从free_msinfoq中获取一个free的mslab挂到 ctable[cid]->partial_msinfoq, to 1.
3. 如果上面两步都失败, 则 slab_drain()
如果还有空闲的dslab, 直接把这个mslab刷到dslab.
如果没有:
slab_evict //先回收一块磁盘上的空间. (这会导致写操作的时候有读)
_slab_drain //把一个写满的mem_slab刷盘.
- pwrite
这里我主要分析mem-slab和disk-slab交换的过程, 在如下时刻都是转折点:
- 启动后第一个插入操作.
- mem-slab用光, 开始启用第一个disk-slab
- disk-slab用光, 开始会对disk-slab做回收.
下面举例:
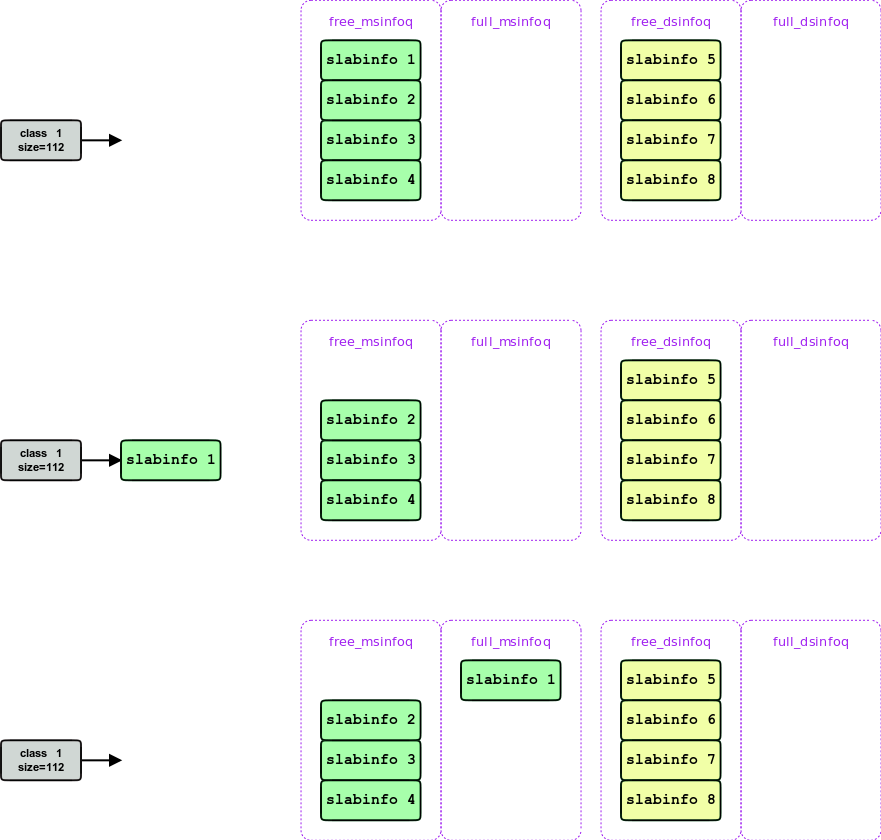
在获取slab的过程中, 我们假设 假设每次写操作都希望获得一个size为100的item, 这样就只会涉及到一个slab class.( ctable[1] )
第一次写, 发现 ctable[1]->partial_msinfoq 为空, 于是从 free_msinfoq 中拿一个挂到 ctable[cid]->partial_msinfoq , 并从这个slab中分配一个item, 写入数据, 这样一直写, 直到这个slab写满, 就把它移到full_msinfoq, 并获取下一个free_msinfoq
这个过程如下图:
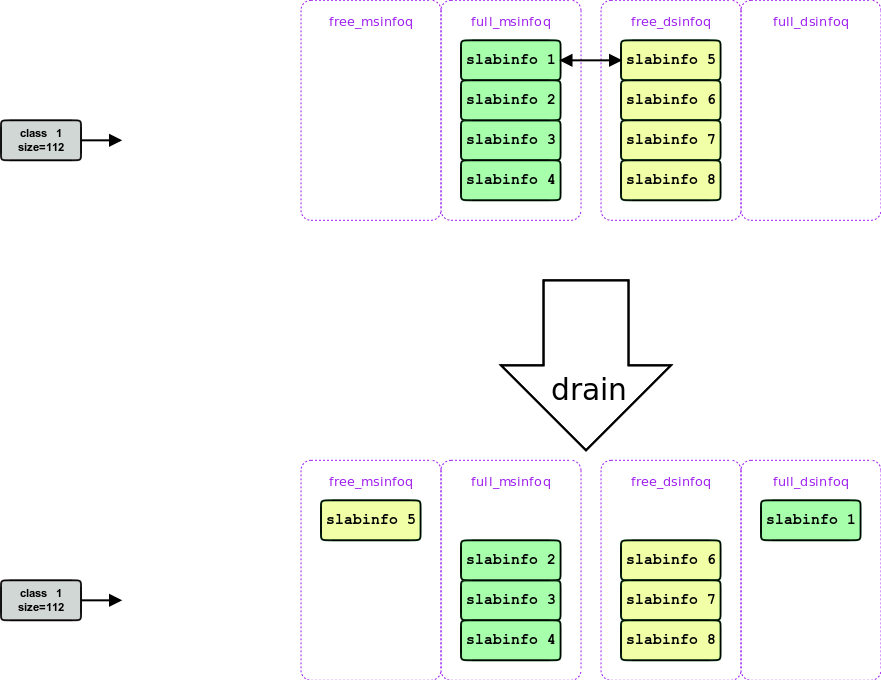
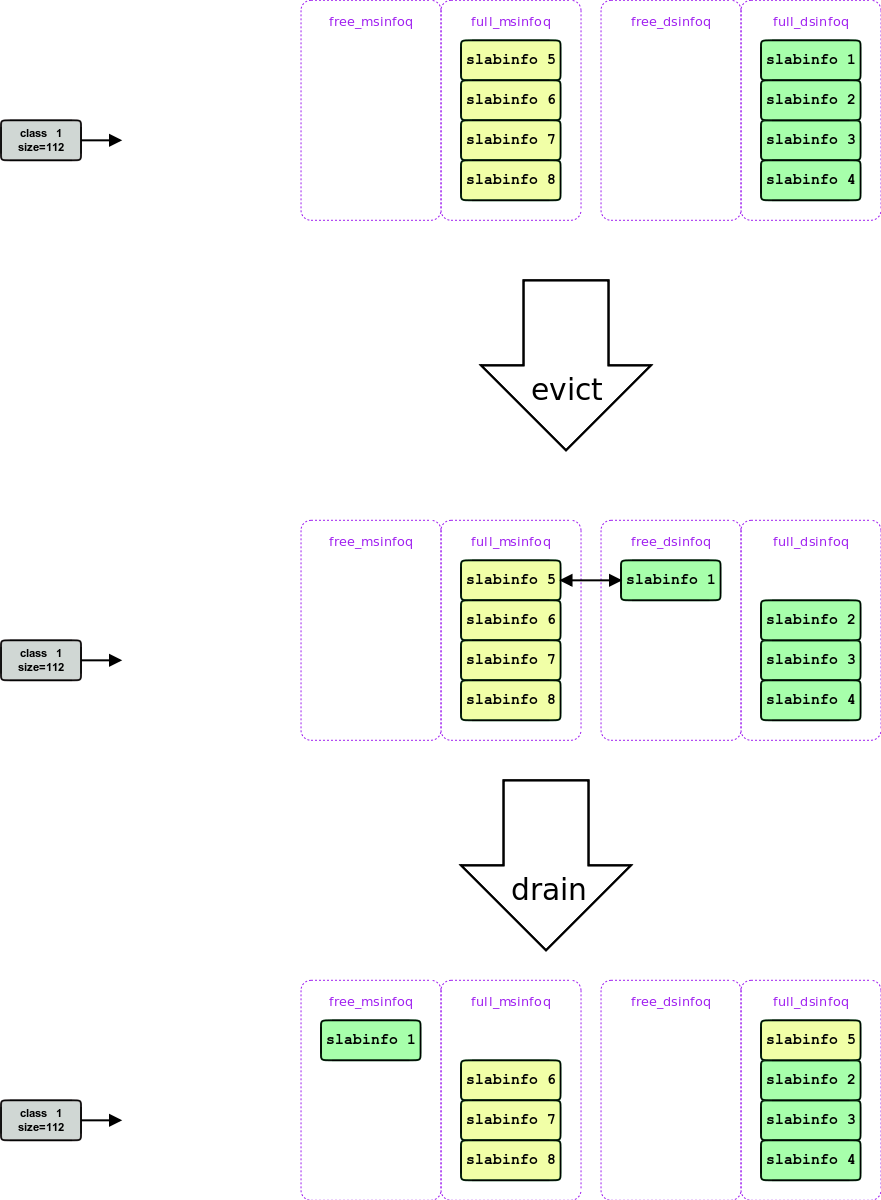
当mem-slab用光后, 就会开始使用disk-slab, 这是通过一次drain实现的, drain 会找到一个free 的disk-slab, 把它刷到这个disk-slab对应的磁盘上, 这样就产生了一个free-mem-slab 和一个full-disk-slab.
此后full_msinfoq 就一直处于空的状态, 每次需要一个slab, 都发生一次drain, 每次drain都会消耗一个disk-slab, 如下图:
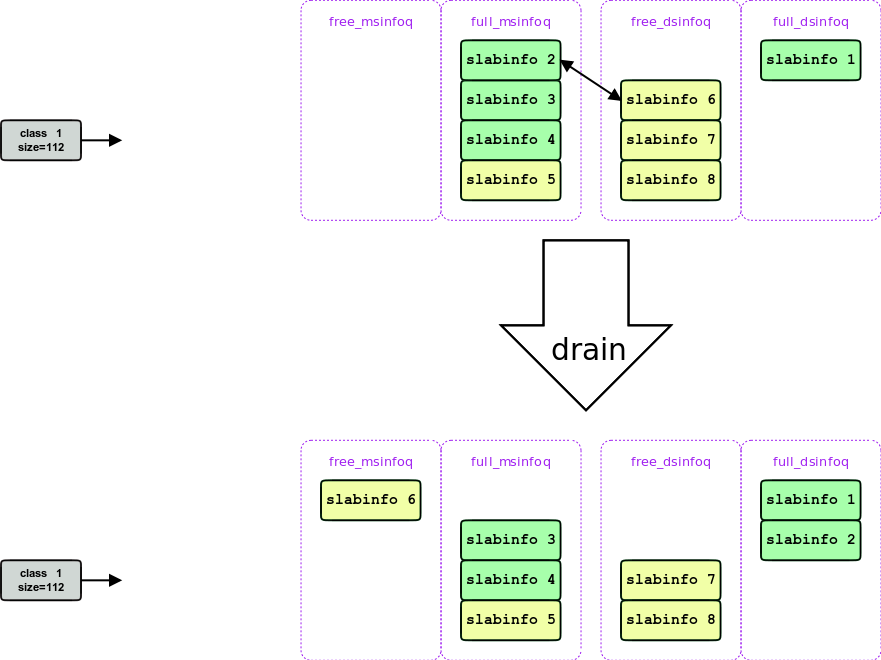
再过了一段时间, disk-slab用光, 此时mem-slab 和disk-slab都full, 此时为了获得一个disk-slab, 就会发生一次 evict, 驱逐掉一个disk-slab中的数据(最老的) 获得一个free-disk-slab, 然后回到2, 获得一个free-mem-slab
- 这里是一种fifo的淘汰, 比较悲剧?
4 性能测试
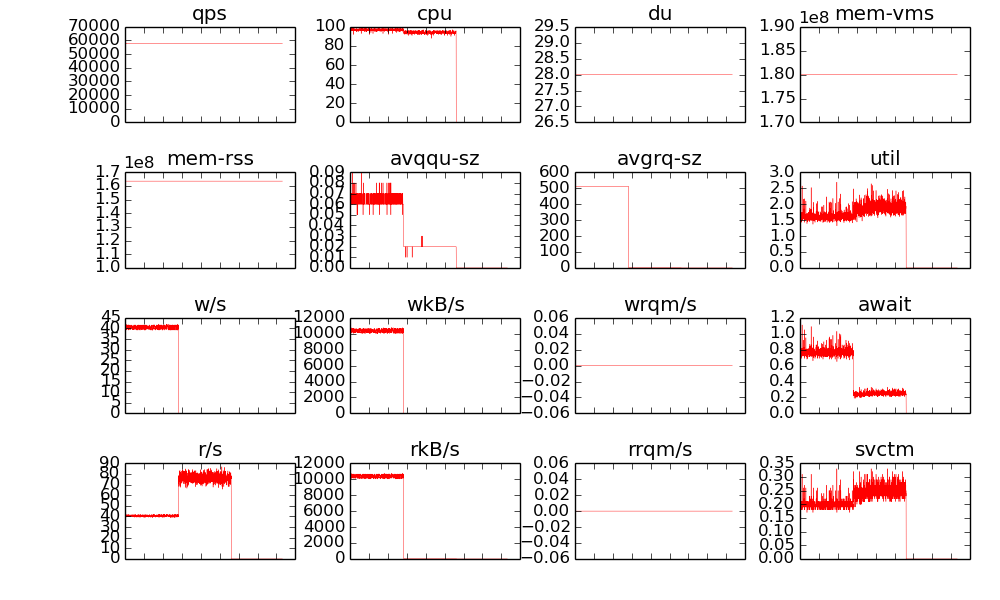
我的性能测试, 先set 10亿条100字节的数据, 再来get:
num = 1000000000 #10亿 cmd = 'mc-benchmark -p 11211 -n %s -r %s -d 100' % (num, num)
发现, fatcache始终能维持5w+的 写入和读取, 但是问题是, 读压力的时候, 磁盘的read-iops才不到100, 这很不合理. 具体原因没有仔细追查.
因为 -n 1000000000 -r 100000000000 的话, 命中率只有1%. 很多查询通过内存就能发现key不存在, 根本不需要访问ssd.
benchmark的结果(图中前半段是写入, 后半段是读取, 读取时的r/s很低, 不能解释):
5 小结
- 限制: item (key+value必须小于一个slab)
- disk-slab的回收是fifo, 这不好.
- 裸写设备的方法, 虽然能更好的利用磁盘的iops, 但是我不太喜欢.
- fc 不会持久化, 虽然它写磁盘, 但是它重启的时候, 是默认把所有slab都标记为free.
- 用 sha1 做index里面的key, 也是一个不好的地方
6 TODO
问题:
- 从代码看, 应该是现有twemproxy, 后有fatcache.
- 如何处理expire, 参看 req_process_get
- 目测get的时候一个kv, 只能放在一个mbuf里面 rsp_send_value?
- 没有主从同步等机制.
小结:
- 自己管理实现存储引擎, 需要关注空间分配, 回收, 索引等, 略复杂, 用levelDB是比较好的方案. 不用关注这一层的细节.