reading: coding-for-ssd & implement a kv
Table of Contents
- 1 Coding for SSDs
- 1.1 Part 1: Introduction and Table of Contents
- 1.2 Part 2: Architecture of an SSD and Benchmarking
- 1.3 Part 3: Pages, Blocks, and the Flash Translation Layer
- 1.4 Part 4: Advanced Functionalities and Internal Parallelism
- 1.5 Part 5: Access Patterns and System Optimizations
- 1.6 Part 6: A Summary – What every programmer should know about solid-state drives
- 1.7 小结
- 2 Implementing a Key-Value Store(FelixDB)
- 2.1 1 What are key-value stores, and why implement one?
- 2.2 2 Using existing key-value stores as models
- 2.3 3 Comparative Analysis of the Architectures of Kyoto Cabinet and LevelDB
- 2.4 4 API Design
- 2.5 5 Hash table implementations
- 2.6 -6 Implementing a memory-efficient hash table stored on the file system
- 2.7 7 Memory Management
- 2.8 8 Networking
- 2.9 9 Interfaces: REST, memcached, etc.
- 2.10 10 Going further
- 2.11 小结
- 3 参考
1 Coding for SSDs
http://codecapsule.com/2014/02/12/coding-for-ssds-part-1-introduction-and-table-of-contents/
1.2 Part 2: Architecture of an SSD and Benchmarking
两种flash:
- NOR flash
- NAND flash (主流)
- 寿命有限, Each cell has a maximum number of P/E cycles (Program/Erase)
- 高温会导致数据清除.
存储单元类型:
- 1 bit per cell (single level cell, SLC ), 寿命相对较长
- 2 bits per cell (multiple level cell, MLC ), 成本低
- 3 bits per cell (triple-level cell, TLC ).
MLC/TLC成本较低 目前多数是MLC或TLC, 如果update很多的话, 还是SLC好.
1.2.1 ssd 架构
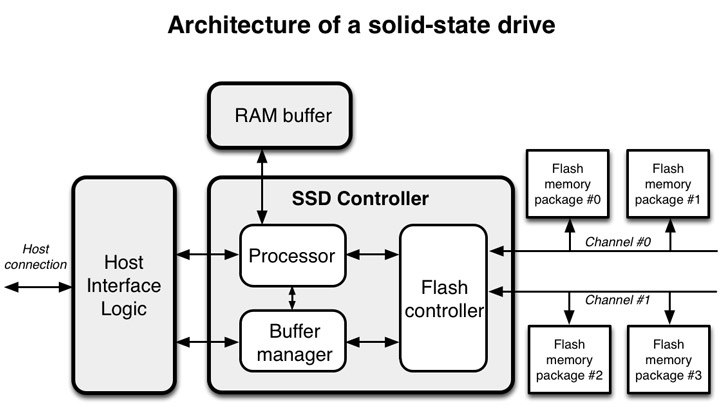
- 接口主要是 Serial ATA (SATA), PCI Express (PCIe), 现在还有新的SAS.
- 通常都有RAM存储(256M+), 用作buffer/cache/map关系等
厂商给的数字通常是在某种条件下测得的, 不见得能表示真实性能:
In his articles about common flaws in SSD benchmarking [66], Marc Bevand mentioned that for instance it is common for the IOPS of random write workloads to be reported without any mention of the span of the LBA, and that many IOPS are also reported for queue depth of 1 instead of the maximum value for the drive being tested. There are also many cases of bugs and misuses of the benchmarking tools. Correctly assessing the performance of SSDs is not an easy task.
span
queue-depth很重要.
测试时间, 和SSD的size有很大关系:
the performance of SSDs only drops under a sustained workload of random writes, which depending on the total size of the SSD can take just 30 minutes or up to three hours
如下图, 30min后性能有明显下降:
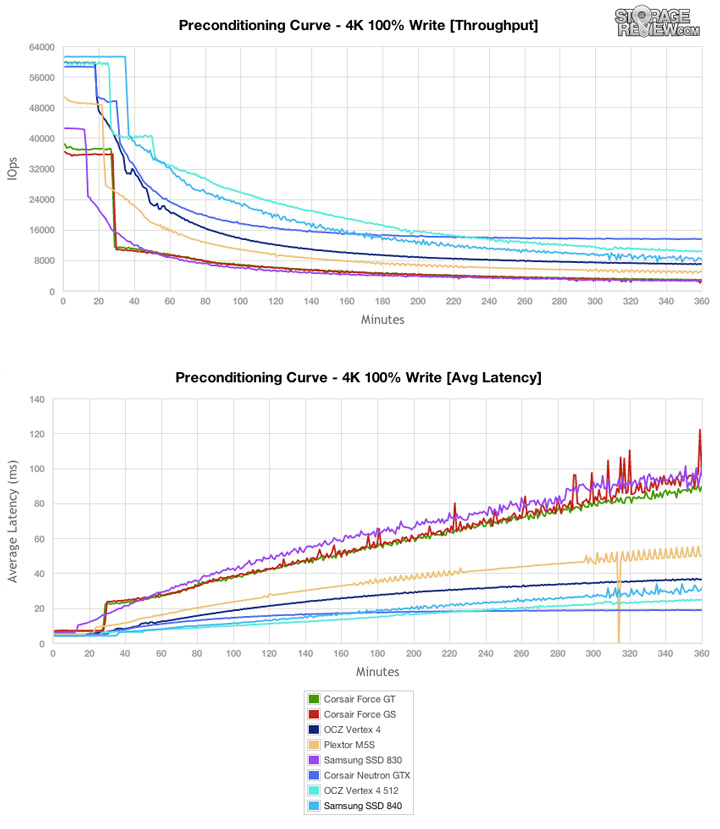
- 原因:
- garbage collection must erase blocks as write commands arrive, therefore competing with the foreground operations from the host,
- GC影响正常流量.
1.2.2 如何做benchmark:
The parameters used are generally the following: - The type of workload: can be a specific benchmark based on data collected from users, or just only sequential or random accesses of the same type (ex: only random writes) - The percentages of reads and writes performed concurrently (ex: 30% reads and 70% writes) - The queue length: this is the number of concurrent execution threads running commands on a drive - The size of the data chunks being accessed (4 KB, 8 KB, etc.)
结果: - Throughput (对顺序读写) - ipos (对随机读写) - Latancy
1.3 Part 3: Pages, Blocks, and the Flash Translation Layer
不少概念:
- how writes are handled at the page and block level,
- write amplification
- wear leveling
- Flash Translation Layer (FTL),
- logical block mapping
- garbage collection
1.3.1 基本操作
- Reads are aligned on page size (It is not possible to read less than one page at once.)
- 和hdd其实一样.
- Writes are aligned on page size
每次读一个page比较好理解, 每次怎么写一个page??
write amplification(写放大)
- 写操作不是直接覆盖原来的page, 而是 拷贝这个page到ssd的RAM中, 在RAM中修改, 最后写到一个新的page里面去.
- When data is changed, the content of the page is copied into an internal register, the data is updated, and the new version is stored in a “free” page, an operation called “read-modify-write”. The data is not updated in-place, as the “free” page is a different page than the page that originally contained the data. Once the data is persisted to the drive, the original page is marked as being “stale”, and will remain as such until it is erased.
- Erases are aligned on block size
- 对于write造成的 stale 状态的page, 需要一个erase操作, 变成 free 状态.
- 但是, 又不能Erase单独的一个Page, 只能Erase整个block.
- 这些都是由ssd控制器的garbage collection process来处理的, 所以这里有很多各种算法(因为寿命有限, 所以寿命管理也需要复杂算法)

1.3.3 wear leveling
写均衡. 避免总是写同一个page.
1.3.4 Flash Translation Layer (FTL)
Flash Translation Layer 是一个地址映射机制, 提供像磁盘一样的逻辑地址.
- logical block mapping
一个逻辑地址到page的有映射表.
This mapping table is stored in the RAM of the SSD for speed of access, and is persisted in flash memory in case of power failure.
When the SSD powers up, the table is read from the persisted version and reconstructed into the RAM of the SSD
- block-level mapping or page-level mapping
page-level 太费内存. Let’s assume that an SSD drive has 256 pages per block. This means that block-level mapping requires 256 times less memory than page-level mapping
block-level 让写放大更加明显
- log-block mapping
- which uses an approach similar to log-structured file systems. Incoming write operations are written sequentially to log blocks. When a log block is full, it is merged with the data block associated to the same logical block number (LBN) into a free block
- log-block mapping 应该是现在ssd写能达到和读一样性能的关键点.
- This allows random writes to be handled like sequential writes.
- 但是read requests need to check both the log-block mapping table and the data-block mapping table, 性能损耗应该很小.
garbage collection.
做ssd控制器的厂商比较少:
seven companies are providing controllers for 90% of the solid-state drive market(做ssd的厂商很多, 但是做控制芯片/算法的很少)
Erase: 1500-3500 μs Write: 250-1500 μs
A less important reason for blocks to be moved is the read disturb. Reading can change the state of nearby cells, thus blocks need to be moved around after a certain number of reads have been reached [14].
1.4 Part 4: Advanced Functionalities and Internal Parallelism
1.4.1 TRIM 命令
which can be sent by the operating system to notify the SSD controller that pages are no longer in use in the logical space
帮助控制器更好的GC.
The TRIM command will only work if the SSD controller, the operating system, and the filesystem are supporting it.
Under Linux, support for the ATA TRIM was added in version 2.6.33 . ext2 and ext3 filesystems do not support TRIM, ext4 and XFS , among others, do support it.
1.4.2 over-provisioning
Over-provisioning is simply having more physical blocks than logical blocks, by keeping a ratio of the physical blocks reserved for the controller and not visible to the user. Most manufacturers of professional SSDs already include some over-provisioning, generally in the order of 7 to 25%
1.4.3 Secure Erase
Some SSD controllers offer the ATA Secure Erase functionality
1.4.4 Internal Parallelism in SSDs
Due to physical limitations, an asynchronous NAND-flash I/O bus cannot provide more than 32-40 MB/s of bandwidth [5].
所以实际上, ssd控制器内部有多个芯片, 类似raid那样.
1.5 Part 5: Access Patterns and System Optimizations
1.5.1 访问模式
在ssd里面, 因为映射关系是动态的, contiguous addresses in the logical space may refer to addresses that are not contiguous in the physical space.
- 避免随机small write.
- amall write 实际上需要写整个block. 所以写一个小数据和一个大数据都需要同样的copy-erase-write操作
- 需要大量操作映射关系表.
- Reads are faster than writes
- 顺序读比随机读throughput好.
- 其它优化
- 对齐读写(有比较小的提升)
- 打开 TRIM
- IO scheduler, (默认是CFQ, NOOP or Deadline 会好一些)
- 尽量不要用ssd存临时文件或做swap (写次数有限)
1.7 小结
- ssd在大量写压力下, 性能可能恶化到8000iops.
- 因为很多update, GC可能跟不上, 如果每次写操作需要做一次erase整个block, 就悲剧了.
- 正常情况下, GC利用后台的时间, 可以完成erase工作.
- The TRIM command and over-provisioning are two great ways to reduce this effect, and are covered in more details in Sections 6.1 and 6.2.
- 写放大, 写一个字节也会导致整个page的read-modify-write
- 应该尽量避免 small write.
很多ssd会通过hybrid log-block mapping来做写merge. 从而减轻写放大.
ssd 适合写少, 读多的情况
我们到底要不要避免用small write 呢?
- 如果没用 hybrid log-block mapping , 明显是要避免small-write.
- 如果有 hybrid log-block mapping 呢? 小的写操作还是没有大的写操作效率高.
2 Implementing a Key-Value Store(FelixDB)
http://codecapsule.com/2012/11/07/ikvs-implementing-a-key-value-store-table-of-contents/
July 8, 2014: I am currently implementing the key-value store and will write a post about it when it’s done
1-4: 作者选了半天名字, api形式, 命名风格....
2.1 1 What are key-value stores, and why implement one?
练习目的:
I am starting this project as a way to refresh my knowledge of some fundamentals of hardcore back-end engineering
Reading books and Wikipedia articles is boring and exempt of practice
- 练习点
- The C++ programming language
- Object-oriented design
- Algorithmics and data structures
- Memory management
- Concurrency control with multi-processors or multi-threading
- Networking with a server/client model
- I/O problems with disk access and use of the file system
现有的: Redis, MongoDB, memcached, BerkeleyDB, Kyoto Cabinet and LevelDB.
打算提供的特性: - Adapt to a specific data representation (ex: graphs, geographic data, etc.) - Adapt to a specific operation (ex: performing very well for reads only, or writes only, etc.) - Offer more data access options. For instance in LevelDB, data can be accessed forward or backward, with iterators
貌似没有什么特点..
- I will use a hash table for the underlying data Structure, the data will be persistent on disk, and a network interface will also be implemented.
- 不求速度 I will not run for absolute speed
- 将基于一个现有c/c++项目(见第2节)
2.2 2 Using existing key-value stores as models
- One of the most memorable projects is DBM, the initial database manager coded by Kenneth Thompson for Unix version 7 and released in 1979
主要考察:
DBM
Berkeley DB , 当时作为改进的DBM
- Kyoto Cabinet, 主要考察对象
- (a straightforward implementation of DBM)一般性能7w/s, 在超过某一个buckets值之后有性能问题
- hash 或者B+ tree.
- LevelDB 主要考察对象
- LSM structures are allegedly optimized for SSD drives [13].
- 有测试, 当条目数从1e6 到1e9的时候, 性能有下降: 找不到原始文章了
- 作者认为LevelDB 代码很好: it is just pure beauty. Everything is clear, simple, and logical.
Memcached and MemcacheDB
MongoDB
Redis
OpenLDAP
SQLite
2.3 3 Comparative Analysis of the Architectures of Kyoto Cabinet and LevelDB
分成这些模块:
- Interface, Get/Put/Delete
- 配置参数
- String库
- Logging
- Compression
- Checksum
- Data Storage
- Data Structure Hash/B+Tree/LSM-Tree
- Memory Management
- Iteration
- Lock 管理
- Error管理
- Transaction
- Comparators
- Snapshot
- Sharding
- Replication
- Testing
太多了... 后面4个不该考虑.
作者认为Kyoto Cabinet 代码耦合较重, 比如: such as the definition of the Parametrization module inside the Core.
String库: - LevelDB is using a specialized class called “Slice - Kyoto Cabinet is using std::string
Memory Management - Kyoto Cabinet 用mmap() - LevelDB: 用LSM-tree
Data Storage
- Kyoto Cabinet, LevelDB, BerkeleyDB, MongoDB and Redis are using the file system to store the data. Memcached, on the contrary, is storing the data in memory (RAM).
- 对Redis 说错了.
关于代码:
Kyoto Cabinet 会把实现写在.h里面, Kyoto Cabinet 代码比Tokyo Cabinet好多了(The overall architecture and naming conventions have been greatly improved.) 但是还是很糟糕:
embcomp, trhard, fmtver(), fpow()
LevelDB 的代码命名就很好.
Kyoto Cabinet 的代码重复也很严重.
2.4 4 API Design
- Opening and closing a database
- Reading and writing data to a database
- Iterating over the full collection of keys and values in a database
- Offer a way to tune parameters
- Offer a decent error notification interface
作者考虑的: Kyoto, LevelDB, BDB, SQLite, 都是库的形式.
LevelDB 的api有open(). 但是没有close(), 关闭的时候是通过delete 指针做的 -> 不对称.
Iteration接口, sqlite 是通过一个回调, 不好:
/* SQLite3 */
static int callback(void *NotUsed, int argc, char **argv, char **szColName) {
for(int i = 0; i < argc; i++) {
printf("%s = %s\n", szColName[i], argv[i] ? argv[i] : "NULL");
}
printf("\n");
return 0;
}
char *query = “SELECT * FROM table”;
sqlite3_exec(db, query, callback, 0, &szErrMsg);
it's always interesting to see how different engineers solved the same problems.
小结: 作者很喜欢LevelDB的api. 除了没有close.
2.5 5 Hash table implementations
这都研究cache line的优化去了, 每必要把.
- gcc4.8中stl 的 hash
2. sparsehash库, 提供 sparse_hash_map 和 dense_hash_map两个类. 其中dense_hash_map可以scales up or down
- Kyoto Cabinet 中的HashDB
- 不会自动扩容.
- 一旦冲突后, 性能就很差.
- it is very difficult to allow the bucket array to be resized for an on-disk hash table implementation
- 把hash表存在磁盘里面, 导致一旦冲突, 就需要在磁盘中访问链表, 这是严重的随机IO
- 所以, 基于ssd的cache应该优化: 读操作最多进行多少次IO .
- 碎片: 有磁盘整理
- 一个基于磁盘的存储引擎确实较复杂.
也许我们能设计这样一个引擎:
- hash表放在内存, 对hash的所有操作写aof(像redis一样)
- 数据操作直接写磁盘.
- 如何解决碎片.
3 参考
这里有很多ssd测试数据: http://www.storagereview.com/samsung_ssd_840_pro_review